利用故事性强和趣味性浓的书籍中搭建诗词背后的历史框架。
推荐书单
♦️Top1:《鲜衣怒马少年时1、2》
♦️Top2:《枕上诗书——遇见最美唐诗》
《枕上诗书——遇见最美宋词》
》
♦️Top3:《唐诗背后那些有趣的灵魂》
《宋词背后那些有趣的灵魂》
到京城四少王维,再从放荡不羁李白到朦胧诗派李商隐…
——宋朝:从歌女之友柳永到人性之光范仲淹
,再从生活虐我千百遍,我待生活如初恋的苏轼…
你们想了解这些诗词大咖们的爱恨情仇,这三套书统统给你安排的明明白白。
分享个人经验,保留阅读记录,做时间的朋友
利用故事性强和趣味性浓的书籍中搭建诗词背后的历史框架。
推荐书单
♦️Top1:《鲜衣怒马少年时1、2》
♦️Top2:《枕上诗书——遇见最美唐诗》
《枕上诗书——遇见最美宋词》
》
♦️Top3:《唐诗背后那些有趣的灵魂》
《宋词背后那些有趣的灵魂》
到京城四少王维,再从放荡不羁李白到朦胧诗派李商隐…
——宋朝:从歌女之友柳永到人性之光范仲淹
,再从生活虐我千百遍,我待生活如初恋的苏轼…
你们想了解这些诗词大咖们的爱恨情仇,这三套书统统给你安排的明明白白。
")
")
")
")
")
")
")
")
提升度 (A→B)>1:代表有提升;
提升度 (A→B)=1:代表有没有提升,也没有下降;
提升度 (A→B)<1:代表有下降。
")
")
")
#包安装 我们使用efficient-apriori,python中也可以利用apyori库和mlxtend库pip install efficient-apriori
#加载包from efficient_apriori import apriori
‘’‘apriori(transactions: typing.Iterable[typing.Union[set, tuple, list]], min_support: float=0.5, min_confidence: float=0.5, max_length: int=8, verbosity: int=0, output_transaction_ids: bool=False)上面就是这个函数的参数min_support:最小支持度min_confidence:最小置信度max_length:项集长度‘’‘
# 构造数据集data = [('牛奶','面包','尿不湿','啤酒','榴莲'), ('可乐','面包','尿不湿','啤酒','牛仔裤'), ('牛奶','尿不湿','啤酒','鸡蛋','咖啡'), ('面包','牛奶','尿不湿','啤酒','睡衣'), ('面包','牛奶','尿不湿','可乐','鸡翅')]#挖掘频繁项集和频繁规则itemsets, rules = apriori(data, min_support=0.6, min_confidence=1)#频繁项集print(itemsets){1: {('啤酒',): 4, ('尿不湿',): 5, ('牛奶',): 4, ('面包',): 4}, 2: {('啤酒', '尿不湿'): 4, ('啤酒', '牛奶'): 3, ('啤酒', '面包'): 3, ('尿不湿', '牛奶'): 4, ('尿不湿', '面包'): 4, ('牛奶', '面包'): 3}, 3: {('啤酒', '尿不湿', '牛奶'): 3, ('啤酒', '尿不湿', '面包'): 3, ('尿不湿', '牛奶', '面包'): 3}}itemsets[1] #满足条件的一元组合{('啤酒',): 4, ('尿不湿',): 5, ('牛奶',): 4, ('面包',): 4}itemsets[2]#满足条件的二元组合{('啤酒', '尿不湿'): 4,('啤酒', '牛奶'): 3,('啤酒', '面包'): 3,('尿不湿', '牛奶'): 4,('尿不湿', '面包'): 4,('牛奶', '面包'): 3}itemsets[3]#满足条件的三元组合{('啤酒', '尿不湿', '牛奶'): 3, ('啤酒', '尿不湿', '面包'): 3, ('尿不湿', '牛奶', '面包'): 3}#频繁规则print(rules)[{啤酒} -> {尿不湿}, {牛奶} -> {尿不湿}, {面包} -> {尿不湿}, {啤酒, 牛奶} -> {尿不湿}, {啤酒, 面包} -> {尿不湿}, {牛奶, 面包} -> {尿不湿}]
#我们把max_length=2这个参数加进去看看itemsets, rules = apriori(data, min_support=0.6,min_confidence=0.5,max_length=2)#频繁项集print(itemsets){1: {('牛奶',): 4, ('面包',): 4, ('尿不湿',): 5, ('啤酒',): 4, ('R',): 4}, 2: {('R', '啤酒'): 4, ('R', '尿不湿'): 4, ('R', '牛奶'): 3, ('R', '面包'): 3, ('啤酒', '尿不湿'): 4, ('啤酒', '牛奶'): 3, ('啤酒', '面包'): 3, ('尿不湿', '牛奶'): 4, ('尿不湿', '面包'): 4, ('牛奶', '面包'): 3}}#通过这个数据我们可以看到,项集的长度只包含有两个项了")
#把电影数据转换成列表 data = [['葛优','黄渤','范伟','邓超','沈腾','张占义','王宝强','徐峥','闫妮','马丽'], ['黄渤','张译','韩昊霖','杜江','葛优','刘昊然','宋佳','王千源','任素汐','吴京'], ['郭涛','刘桦','连晋','黄渤','徐峥','优恵','罗兰','王迅'], ['黄渤','舒淇','王宝强','张艺兴','于和伟','王迅','李勤勤','李又麟','宁浩','管虎','梁静','徐峥','陈德森','张磊'], ['黄渤','沈腾','汤姆·派福瑞','马修·莫里森','徐峥','于和伟','雷佳音','刘桦','邓飞','蔡明凯','王戈','凯特·纳尔逊','王砚伟','呲路'], ['徐峥','黄渤','余男','多布杰','王双宝','巴多','杨新鸣','郭虹','陶虹','黄精一','赵虎','王辉'], ['黄渤','戎祥','九孔','徐峥','王双宝','巴多','董立范','高捷','马少骅','王迅','刘刚','WorapojThuantanon','赵奔','李麒麟','姜志刚','王鹭','宁浩'], ['黄渤','徐峥','袁泉','周冬雨','陶慧','岳小军','沈腾','张俪','马苏','刘美含','王砚辉','焦俊艳','郭涛'], ['雷佳音','陶虹','程媛媛','山崎敬一','郭涛','范伟','孙淳','刘桦','黄渤','岳小军','傅亨','王文','杨新鸣']] #算法应用 itemsets, rules = apriori(data, min_support=0.5, min_confidence=1) print(itemsets){1: {('徐峥',): 7, ('黄渤',): 9}, 2: {('徐峥', '黄渤'): 7}} print(rules) [{徐峥} -> {黄渤}]
转自:https://mp.weixin.qq.com/s/2iNO3som2MUnhJroMn9y5Q
对于量化投资,Pythoner 学习流程一般可以分为如下六个部分。1)了解基础语法和数据结构。2)掌握Pandas的使用基础并进阶。3)掌握统计理论及金融学术理论。4)掌握金融量化实践、策略研究理论。5)学习回测平台开发。6)学习平台开发。
广义,凡是借助于数学模型和计算机实现的投资方法都可以称为量化投资。
国内比较常见的量化投资方法包括股票多因子策略(阿尔法)、期货CTA策略、套利策略和高频交易策略等
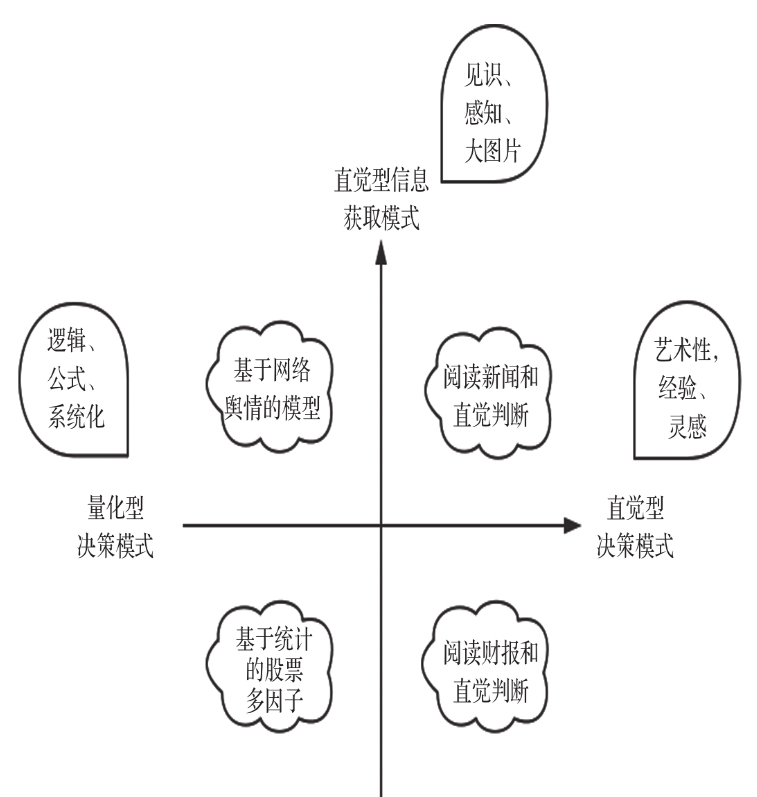
量化投资策略的最大特点是其具有一套基于数据的完整交易规则。
量化投资的优势可以总结为三个词:客观性、大数据、响应快。量化投资一般通过回测来证实或者证伪策略的历史有效性;在研究或者决策中,通常会引入大量的数据来进行分析。;用计算机进行自动分析,所以分析和响应速度都十分迅速,一般能达到秒级,高频交易甚至是以微秒为单位的。
夏普比率是一种衡量策略表现是否优秀的常用指标,夏普值越高表示策略越优秀。
投资不是“优化”问题,投资是“预测”问题,是要预测市场的下一步应该怎么走。
AI在金融投资领域最大的问题是,可用的样本数据极其有限,也无法大量生成。股市有多少历史数据,就有多少样本数据,但也只有这么多。极其有限的样本数据,加上极其庞大的特征维度,是AI在金融预测建模上举步维艰的根本原因。众所周知的是,训练数据是AI的基本养料,数据有限,就会导致模型很难得到大幅度的提升。就那么多有效的因子,大家反复挖掘,失效的速度也越来越快。
在数据分析领域(包括量化投资),编程语言具有两大作用,一个是科学计算、统计等算法层面,主要用于业务的相关研究;另一个是系统应用开发,主要用来搭建基础IT设施,比如数据库、交易平台等。
python是坠吼滴
python 3.x ;Anaconda;IDE()
NumPy(Numerical Python的简称)是高性能科学计算和数据分析的基础包
SciPy 是基于NumPy的,提供了更多的科学计算功能,比如线性代数、优化、积分、插值、信号处理等。
Pandas具有NumPy的ndarray所不具有的很多功能,比如集成时间序列、按轴对齐数据、处理缺失数据等常用功能
StatsModels是Python的统计建模和计量经济学工具包,包括一些描述统计、统计模型估计和推断。一般来讲,StatsModels能够很好地满足各类研究人员的统计计算需求。
DataFrame是一个表格型的数据结构

对于DataFrame数据类型,可以使用[]运算符来进行选取,这也是最符合习惯的。但是,对于工业代码,推荐使用loc、iloc等方法。因为这些方法是经过优化的,拥有更好的性能。
Python的可视化分析最底层的库是Matplotlib
Pandas 简单的可视化
seaborn 统计可视化库
本质都是调用 Matplotlib
散点图是最常用的探索两个数据之间相关关系的可视化图形
直方图主要用于研究数据的频率分布
Matplotlib和seaborn的中文乱码问题的解决方案。第一种是在画图的时候指定字体,第二种是修改配置文件
seaborn已经封装好了很多功能,在进行可视化分析时,优先考虑使用seaborn
javascript 中的 highcharts可以绘制很多动态的可视化图形,进行数据可视化研究非常方便。https://www.highcharts.com/stock/demo/intraday-candlestick
python 调用highcharts :https://github.com/kyper-data/python-highcharts/blob/master/examples/highstock/candlestick-and-volume.py
以下都是numpy库内函数
rand和random_sample都是均匀分布(uniform distribution)的随机数生成函数。rand_sample传入一个n维的元组元素作为参数
randn 和 standard_normal是正态分布的随机数生成函数
randint和random_integers是均匀分布的整数生成函数
shuffle可以随机打乱一个数组,并且改变此数组本身的排列。
Permutation用于返回一个打乱后的数组值,但是并不会改变传入的参数数组本身。
N次伯努利试验的结果分布即为二项分布。使用binomial(1,p)即为一次二项分布。使用binomial(1,p,n)即表示生成n维的二项分布数组,也就是伯努利分布。
统计量,就是利用数据的函数变化,从某种维度来反映全体数据集的特征的一种函数。
mean函数可用于计算数组的平均值
median函数可用于计算数组的中位数
std函数用于计算数组的标准差
var函数用于计算数组的方差
频率分布直方图其实是对一个变量的分布密度(分布)函数进行近似估计的一个手段。
np.histogram可以用来计算一位数组的直方图数据
SciPy包含了大量的处理连续随机变量的函数,每种函数都位于与其对应的分布类中。每个类都有对应的方法来生成随机数,从而计算PDF、CDF,使用MLE进行参数估计,以及矩估计等。
回归分析是通过建立模型来研究变量之间的相互关系并进行模型预测的一种有效工具。
案例:以平安银行的月度收益率为例来了解某只股票的风险回报率是否与大盘指数基金风险回报率有关,且相关度有多高?
思考的问题是,如果大盘涨1个点,那么平安银行股票统计概率上会上涨多少点?
假定如下模型:银行月度收益率=α+β*深证成指月度收益率+ε
即平安银行月度收益率与深证成指月度收益率呈线性相关,并且受随机扰动项影响
这又带来了新的问题。这个结论可靠度有多高?这个系数会不会浮动?从历史数据来看,这个浮动区间应该是多少?
能否利用数据来拒绝这一假设。这一类问题,在统计学上统称为假设检验(Hypothesis Testing),为了解决这一问题,需要使用的手段被称为统计推断(Statistical Inference)。
当我们拒绝这个正确的假设时,我们犯的错误,称为第一类错误(Type I Error)
即使假设是错误的,我们也会接受这个假设,这类错误称为第二类错误(Type II Error)
拒绝假设的概率函数称为功效函数(Power Function)。而由于我们无法同时满足最小化两类错误,因此必须要寻找到一个平衡点,以控制更严重的错误,并适当牺牲犯不严重错误的概率。哪一类错误更为严重是根据实际问题来确定的。
常用的设计检测框架的模式是,控制第一类错误的发生概率,并且调节假设,使得发生第一类错误更加严重,这个严重度会得到统计学者的控制。
收集到初步的样本数据之后,接下来需要考虑的几个问题是:样本数据的质量是否有问题,如果有问题,应该怎么处理?样本数据是否出现了意外的情况?样本数据包含哪些基本的统计特征,有没有明显的规律?为了便于后续的深入分析和建模,我们需要对数据进行哪些处理?
数据清理:原始数据的可能问题,数据缺失、噪声或者离群点、数据不一致
中心趋势度量主要包括均值、中位数、众数
数据散布或者发散的度量。这些度量包括方差、极差、分位数等。
方差和标准差是最常见的数据散布度量,它们可用于指出数据分布的散布程序。低标准差意味着数据趋向于非常靠近均值,而高标准差则表示数据散布在一个大的范围中
极差是数据中最大值和最小值的差值,数值X的N个样本x1,x2,…,xN的极差可以记作max(X)-min(X)。
挑选某些数据点,这些数据点刚好可以将数据划分成大小相等的集合,这些数据点称为分位数
直方图是以一种图形方法来概括给定数值X的分布情况的图示。
散点图(scatter plot)是确定两个数值变量X、Y之间看上去是否存在联系,以及具有怎样的相关模式的最有效的图形方法之一
五数概括由中位数、两个四分数、最小、最大值组成
可以将多重索引对象看成是一个由元组(tuple)元素组成的数组,其中,每一个元组对象都是唯一的。MultiIndex既可以由嵌套数组创建(使用MultiIndex.from_arrays),也可以由元组组成的数组创建(使用MultiIndex.from_tuples),或者指定每个维度的索引值,自动循环生成索引(使用MultiIndex.from_product)


转自:https://mp.weixin.qq.com/s/5Oa4dVHjy9GxGy6EzdFUWQ

若比较最低分数线:
闵行(694)>徐汇(690.5)>松江(690)>嘉定(689.5)>奉贤(688)>浦东(687.5)>杨浦(686)>普陀(685.5)>长宁(684.5)>虹口(683.5)>宝山(682)>黄浦(674.5)>青浦(672)>崇明(669.5)>金山(668)>静安(645.5)
闵行的门槛最高,最低的闵行中学分数线达到694分;其次是徐汇,最低的南洋中学分数线为690.5分。可以看出,闵行、徐汇两区的头部中考成绩非常强!
紧随其后的松江、嘉定、奉贤,有一个共同点:本区市重点只有2-3所。市重点数量较少,加上考生人数并不少,竞争相当激烈,因此市重点的门槛自然就不低了。
若比较平均分数线:
徐汇(700.3)>杨浦(699.6)>闵行(698.5)>嘉定(696.5)>浦东(696.4)>普陀(696)>松江(694.5)>长宁(690.2)>宝山(689.9)>虹口(689.8)>奉贤(689)>黄浦(688.8)>青浦(679.5)>静安(679.1)>金山(675)>崇明(669.5)

转自:https://mp.weixin.qq.com/s/BZZ3OB8veh8O57SMF1cWoA