第1章 开启大门 每个人都能提升学习能力
我将大把的时间花在这门专长上,形成了良性循环——学得越好,就越喜欢学;而越喜欢学,就会在它上面花越多的时间。我的成功促成了练习欲望,练习又回馈给我更多的成功。
我认识到,如果能把某些概念和技巧转化为自己的一部分,它们就会成为我的强大武器。同时,我告诉自己,不要试图一口吃个胖子,要给自己充裕的练习时间——就算我的同学会不时地先于我毕业,毕竟我一个学期学不了他们那么多课程。
你的大脑生来
第2章 放松点 有时候太勤奋也是一种病
就配备了非凡的心算能力
大脑中两种思维网络模式:专注模式(focused mode)和发散模式(diffuse mode),它们对学习都非常重要
专注模式下的思维活动对数学和科学的学习必不可少。它是利用理性、连贯、分解的途径直接解决问题的一种模式。专注模式与大脑前额叶皮层(位置就在脑门正后方)集中注意力的能力相关
发散模式对学数学和科学也同样必不可少。如果我们在一个问题上挣扎了许久而不得思路,它会冷不防地提供一个新点悟。同时,它也与宏观视角相关联。当你放松注意力,任由思维漫步时,发散模式思维就出现了。松弛状态让大脑的不同区域得到相互联络的机会,并反馈给我们宝贵的灵感。
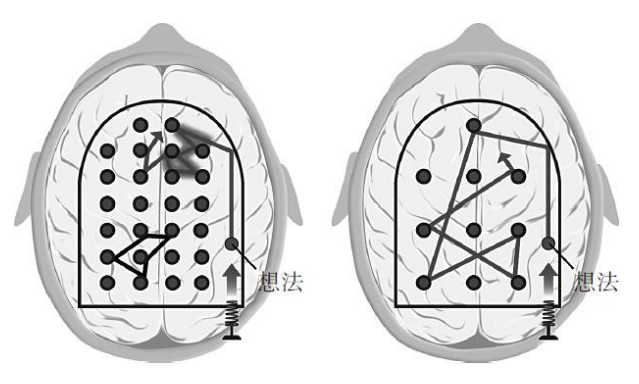
专注模式意味着我们高度专注一个特定问题或者概念。
发散模式则容纳了更为开阔的全局视野。
思维的定式效应(类似一叶障目)。在这种效应里,你脑海中已有的,或是最初的想法,会阻碍你产生更好的想法或答案。
定式(einstellung)一词原为德语,意思是“装置”,基本上你可以理解为先入为主的概念,它会变成未来思维旅途上“装置”好的路障。定式效应往往会成为学生的绊脚石。
在学习新东西的时候,你必须得让错误的旧观点“改过自新”。
学数学和科学的学生常犯的一个显著错误:还没学会走就开始跑。换句话说,他们没读教材,没上课,没看在线课程,甚至都没问过那些会的人,就开始盲目地做作业了。这种行为简直是自暴自弃。这跟闭着眼睛不看答案在哪儿,就随机拉下推杆弹出小球有什么区别?
了解如何获得真正的解决办法非常重要
如果你想要理解新事物,那最好关掉精确的专注思考模式,把开关切换到“广角光源”,直到你锁定了一个新的、更有成效的方法。
努力工作时的放松也是一个重要环节,当然,更是令工作卓有成效的关键。
大脑的左半球与慎重的、注意力高度集中的事项联系更紧密。它似乎也更擅长处理连贯性的、富于逻辑性的思考
与大脑的右半球相关的,则更多是像四处扫视环境、与他人互动或是处理情绪之类的活动。同时,应对即刻发生的活动或是宏观问题的处理也与大脑的右半球相关。
无论是专注模式,还是发散模式,都要求两个大脑半球同时参与。想要学习数学和科学,而且保持创造力,两种思维模式都会被用到,对它们的强化训练缺一不可。
面对一个困难的问题时,我们必须先要用专注模式奋斗上一阵子,投入艰苦的努力。
困惑是学习过程中的有益部分。
学习本来就是从困惑中摸索问题答案的过程,能够描述出来问题就已经成功了一半。只要发现了困扰你的东西是什么,那么你就离解答出来不远了
如果拖延,你就没有时间供专注模式稳扎稳打,只够走马观花地过上一遍。这样也会增加你的压力,因为你清楚自己必须完成一个很讨厌的任务。其中的神经模型会变得模糊黯淡、残缺不全,你的思维基础七零八落、摇摇欲坠。这可不是个小问题,尤其对于数学和科学来说更是如此
哪种神经模式都需要时间,可你根本就没有给自己留出余闲。
关掉手机,或是任何其他会发出提示音或闪烁的干扰源,用一个计时器设定25分钟,在这25分钟里,全神贯注于一项任务,什么任务都行。不用担心能不能完成它,专心去做就好。25分钟的时限一到,你就停下来奖励一下自己
第3章 学习即创造 来自托马斯·爱迪生不粘锅的启示
“脑距离模型”假设,脑中两项并行的任务所在的脑区越近,彼此间的相互干扰就越大。两项并行任务使用同一大脑半球时,尤其是同一脑区的情况下,确实会让事情变得一片混乱
只要你放下手中的工作,停下来喘口气,发散模式就会乘虚而入,上蹿下跳,高屋建瓴地搜寻解决方案。
创造力就是对自身能力的驾驭和拓展
发散模式能让你的学习更有深度和创造力,而解决数学和科学问题的背后往往正是创造力在运筹帷幄。
在寻求解答的这场冒险里,每抓住一个错误都是往前进了一步。揪出错误也能带给你成就感。
爱迪生本人就曾宣称“我没有失败。我只是发现了10000种行不通的方法”。
只要放轻松什么都不想,你的大脑就会进入一种自然的默认状态,那就是发散思维的一种形式。
如果要启动发散模式与棘手问题战斗,最有效也最重要的诱发因素还是“睡觉”。
可别指望只靠发散模式,就能轻轻松松地如愿以偿。
要让大脑捕捉问题,首先要借助于专注模式调动全部注意力。
长远看来,在举重练习中间歇性地休息更有益于生长出强壮的肌肉。持之以恒才是关键!
在紧凑的专注模式后,利用发散模式的方法奖励自己
放慢脚步,也许你会得到惊喜:细嚼慢咽反而让你比那些脑子快的同学学习得更深入。帮我武装起大脑的最重要窍门之一,就是不要想一口吃成个胖子。
眨眼是项打破僵局,帮你跳出来重新评估现状的关键行为。闭眼似乎可以在一瞬间放松我们紧绷的注意力,提供片刻休息,并让我们的意识和想法刷新页面
眨眼会暂时性地断开我们与专注模式视角间的连接。但另一方面,刻意闭眼又似乎能帮我们提高专注程度——沉思求解时,人们通常远眺、闭眼或干脆蒙上眼睛来避免干扰
要解出难题或是学会新概念,至少要有一个你在无意识思考的时间段。而正是在这些你并非直接关注的时间间隔里,发散模式得以踱开到一边,用新角度看问题。在此之后,当注意力重新转回到问题上时,你就可以将发散模式传达的新想法和新模型整合起来了。
几个小时就足够发散模式取得重要进展了。当然,时间也不能太长,否则灵感还没来得及传给专注模式就会消逝
学新知识、新概念时,别扔上一天才回头复习。
专注模式下的工作,就像在为砌墙提供砖块,而发散模式则是用泥浆把砖块逐渐结合在一起。保持耐心,一步一个脚印地去做,非常重要。
当你足够深入地把基本概念印刻在心里时,会更易于接受别人的解释。学习往往意味着为吸收的内容赋予意义,那我们总要先摄入一些内容才行
短期记忆是未经主动排演过的激活信息。工作记忆是短期记忆信息的子集。短期记忆信息即注意力集中和主动处理之所在
在大脑中对正在处理的信息进行瞬时以及有意识加工的这部分记忆,叫作工作记忆。
共识是,工作记忆只能容纳四个组块。(人类大脑倾向于自动地将记忆单元打包成组块,因此我们的工作记忆的实际容量要比看起来大很多
如何把工作记忆中的信息留住呢?一般来说,这需要不断地排演重复
长期记忆可以看作仓库。东西一旦存进去,它们通常就一直待在那儿了。这间仓库幽深广阔,可以容纳数十亿件物品,而且包裹很容易因为埋得太深,而难寻踪迹。研究表明,当你的大脑首次把一个信息条目存入长期记忆时,最好时常去看看,以保证日后需要时还能找到它
·间隔性重复有助于把信息从工作记忆转移到长期记忆。
设定一个21分钟的闹铃。小睡时间太长会让人头昏脑涨
人醒着的时候大脑确实会产生有毒物质。而在睡眠中,脑细胞会收缩,于是细胞间隙会变大,这就像是打开了水龙头——脑脊液从中流过并且冲洗掉毒素。
睡眠状态下的部分清理工作就是清除琐碎的记忆,并增强重要的部分。
充足的睡眠能够显著提升人们解决难题、理解知识的能力
·学好数学和科学最好的办法就是“每天进步一点点”。
接受分歧。创新性和“认同度”通常是成负相关的,那些最不受认同的观点很可能会是最有创意的一个。
第4章 组块构建与避免能力错觉 “口默念而心得解”的秘诀
当你将注意力集中于某件事物时,注意力章鱼的神经触手就将大脑的某些特定部分连接起来。
专注模式学习的一个重要部分,就是让注意力把大脑各个部分连接在一起。有趣的是,注意力触手会在紧张状态下失去部分连接能力。这就是当你愤怒、紧张或害怕时,总觉得脑袋有点不够用的原因。
任何专业技能的培养都是积跬步以成千里的过程。
组块是根据意义将信息碎片组成的集合。
思维组块都是绝大多数科学、文学和艺术知识的构成基础。
要熟练地掌握数学和科学知识,就要创造一些概念组块——这是通过意义将分散的信息碎片组合起来的过程。
大量事实证明,获得各种资源更有益于学生加深理解。

构建组块(chunking)(如右图)能帮你利用意义,组合起信息碎片,这是一种心智上的飞跃。新的逻辑整体更便于人们记住组块所包含的信息,也便于将其融入更大的学习背景。
1.进行组块的第一步,就是把注意力集中在需要组块的信息上。着手开始学习新东西,既要创造新的神经模型,也要把新模型和遍布大脑各处的既有模型联结在一起。[7]要是你走神,章鱼触手可就抓不紧了。
2.组块活动的第二步是理解(understanding)。要把基本概念打包成组块,首先要理解这个基本概念。暂时只要求基本理解,即合成信息得出关键要义就好。
理解力就像强力胶,能把基础的记忆痕迹黏合在一起。它铺展出各种各样的痕迹路径,将记忆痕迹联结起来。
3.组块的第三步,是获取背景信息。你所看到的将不仅是如何进行组块,还有何时何地使用它们。在相关或不相关的问题上反复推敲、练习,使你不仅能了解组块的用武之地,也能清楚它何 时派不上用场。这将有助于你在更大的宏观图景中定位新组块。
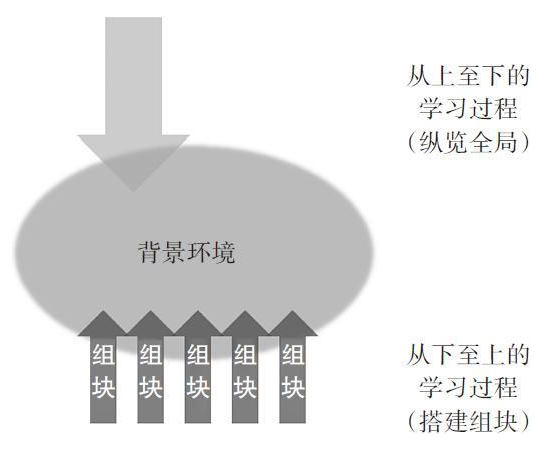
学习活动的发生包括“以上至下、从下至上”两个方向。从下至上的组块过程,是指学习过程中的练习与重复可以帮助建立和加固每个组块。
从上至下“纵览全局”的过程,这一过程能让你看到知识在宏观图景中的位置。
试着回想学习材料,即提取练习(retrieval practice),效果比单纯阅读材料好得多。
看书毕竟比回想简单多了,学生因此执迷于自己的错觉——坚持低效率的学习方式。
“只有用对了学习策略,求知心才不会落个竹篮打水一场空。”
划重点和标下画线一定要谨慎,否则你不仅会效率低下,而且会被误导
在学习中进行回想——让大脑提取关键概念,而非通过重复阅读被动地获取知识,将让你更加集中高效地利用学习时间。下一次重读开始前的间隔时间才是这件事真正有效的部分。利用重读间隔中进行的回想,训练了你的大脑。
你要争取独立解决家庭作业中的数学和科学难题
别扔太久之后才去练习回想,那样你每次都得从头开始巩固概念。特别是对初次学到、还颇有挑战性的知识,最好是24小时内就和它们亲近一下
如果你只是看着答案做题,然后自欺欺人地说“太好了我懂啦”,那么答案根本就不属于你,因为你几乎没有把这些概念编织到基础神经回路上。
你会发现,一旦把首个问题或概念存入脑中的图书馆,不管存入的是什么,第二个概念进入脑中就变得容易一些。第三个同样不会太难。不是因为这些问题本身简单,而是随着你的努力,这一过程变得更轻松了。
如果你能够将脑中存储的大量概念和方法都内化为组块模型,那么发散模式的轻声耳语就会为你指出通往正确答案的路途,而且发散模式还能用新方式连接起两个或以上的组块,帮你解决不同以往的难题。
解题的途径有两种:第一种,是按顺序逐步推理;第二种,是更多跟随整体直觉。
大部分难题都是由直觉解决的,因为它们与你熟知的事物截然不同。[24]要记住,发散思维会以半随机的方式创造联结,所以你需要通过专注模式对它给出的答案仔细验证。直觉并不总是对的!
解决数学和科学难题,就像在钢琴上弹一首曲子。你练得越多,神经模型就越坚实,颜色就越深、越强壮。
一天之内再次强化学习模型,在构造神经模型的起始阶段至关重要。
重复与练习的背后是大脑在创造固化组块,难点就在于它们会让人觉得枯燥乏味。
任何值得去努力的事情,没有重复练习都是不行的。
但在数学和科学的学习中,必须进行适量的练习和重复,否则就无法构建组块来支撑专业技能
相同时间内,仅靠对材料的练习和回想,学生的习得内容和学习深度都远远超过了其他方法
提取知识和回想知识让我们不仅仅是重复的机器——提取过程本身增加了学习深度,并帮助我们逐渐形成组块。
数学和科学中,内化解题办法的真正美妙之处就在于:练得越多,题目就变得越简单,对你的帮助就越大。
要掌握一门新学科,是要学会挑选使用恰当的解题技巧的(不能只会用锤子)。唯一的解决途径就是去练习各种题目,运用不同技巧解决这些问题。
学习期间一旦巩固了一种技巧的基本思路,你就要开始穿插练习不同类型的题目。
与其在同类技巧、概念上投入太长时间去学和练,不如把精力分配到更短的学习时间段上,以避免过度学习
手写比输入能让人更轻松地记住概念
第5章 预防拖延 化“坏”习惯为好帮手
陷入拖延很简单,但获得顽强的意志力可就难得多了。因为后者需要动用大量的神经资源。可以说用意志力来对抗拖延,就像在空中喷洒廉价劣质的空气清新剂一样完全徒劳无功。除非万不得已,否则不要把意志力浪费在抵抗拖延上。
对于大多数人来说,学数学或科学依赖于两个过程:一是短暂的学习期,这是“神经砖块”垒砌的过程;二是学习期之间的间隔,就是“思维水泥”凝固的过程。
现实就是,我们拖延的,往往是让我们感到不安的事情
令人痛苦的就是预感本身。
“对一项任务的恐惧会比这项任务本身消耗更多的时间和能量。”
回避痛苦似乎无可厚非,但习惯性的回避会带来非常糟糕的长期影响。
人们往往讨厌做自己不擅长的事情。但如果你开始对某件事游刃有余,自然就会乐在其中了。
典型的拖延症状。每次想到不怎么喜欢的事都会激活大脑中的痛觉中枢,所以你就会逃到那些令你更开心的事情中去,[8]获得暂时性的感觉良好。
拖延会成瘾。它所提供的片刻兴奋与解脱是乏味现实的避风港。
研究者发现,拖延症不仅可以作为技不如人的借口,甚至会成为虚荣心的温床。
已经习惯性拖延的你会身不由己地寻求那短暂而微小的愉悦感。而这种习惯性反应让你渐渐失去从前的自信,最后干脆不再指望能提高工作效率。这就是为何拖延症患者总宣称自己压力大、身体差、表现不好
我们所拖延的都是感到不舒服的事情。但从长远来看,贪图一时之快未必对我们有益。
·拖延就像在服用微量的毒药。一时看不出影响,但日积月累,危害极大。
第6章 小恶魔无处不在 深入理解拖延的习惯
习惯就是大脑进入了预设好的“小恶魔”状态(即出窍状态)。你也许不足为奇,神经模型从频繁的练习中产生,它们自动联结形成组块,而组块和习惯有着密切的联系。[2]习惯可以帮我们节省力气,它能为我们的大脑腾出空间进行别的活动。
习惯分为四个部分。
1.信号。这就是使你进入“出窍状态”的触发点。信号本身没有好坏之分。你对信号的反应,也就是你的反应程序才是重点。
2.反应程序。这就是你的出窍状态——你的大脑在接到信号暗示时做出的常规性、习惯性的反应。
3.奖励机制。习惯之所以得以发展和继续,是因为它能激励我们,让我们感到愉悦。拖延是一种很容易养成的习惯,因为它会如此迅速地奖励你,把你的注意力转移到更愉快的事情上去。
4.信念。习惯的强大效果,来自你对它的信念。
改变旧习惯的窍门是寻找压力点——你对信号的反应。改变你对信号的反应,是唯一需要动用意志力的环节。
1.信号。识别出让你进入出窍和拖延状态的导火索。信号一般有这么几种:地点、时间、感受、对他人的反应和刚刚发生的事件。养成新信号对他们帮助很大,比如一放学回家就开始写作业,或者在课后休息一下之后马上写作业,效果都非常好。
2.反应程序。这么说吧,你经常会把注意力从学习转移到不太痛苦的事情上。每次得到信号,你的大脑都想自动进入这个反应程序,所以当这个压力点出现的时候,你就必须主动注意去改变旧习惯了。改变的关键在于制订计划。培养新习惯可能会很有用。
3.奖励机制。有时这需要一番调查研究。你为什么要拖延?拖延能不能用情感上的补偿来替代?能不能以那种小有成绩,哪怕是微不足道的自豪感来替代?……
习惯的强大之处在于它能造成神经层面的欲望。要想克服之前的欲望,就再来一个新奖励。只有当你的大脑开始期待这个新奖励,关键的转变才会发生,你才能养成新习惯。
4.信念。改变拖延的习惯,最重要的是要有“自己一定能行”的信念。但你对新系统效果的坚信不疑,能够助你渡过难关。巩固信念的方式之一就是发展一个新的朋友圈。要想培养“我能行”的信念,就要多和抱有这种信念的同学相处。
但你对新系统效果的坚信不疑,能够助你渡过难关。巩固信念的方式之一就是发展一个新的朋友圈。要想培养“我能行”的信念,就要多和抱有这种信念的同学相处。
想要避免拖延,就不要专注于结果。相反,你应该把关注点放在一些过程的形成上——也就是培养一些习惯,这些习惯能让你动手做一些痛苦而又不得不完成的工作。
分享一个很有用的小建议:即刻开始行动。这个建议听起来相当简单,但良好的开端是成功的一半
关键是,干扰也是不可避免的,在它出现的时候你要训练自己无视它。关于克服拖延,我能给你的唯一一个最重要建议就是无视干扰!
一心多用就像不断地揠苗助长。不断地转移注意力,也就意味着你脑中的新观点、新概念没有机会生根发芽。做功课的时候一心多用会让你迅速疲劳。每一次微不足道的注意力转移都会消耗能量
一般来看,我们发现在学习和听课期间一心多用的学生总会不断考出差成绩
练习无视干扰。无视干扰比一开始就用意志力抵抗干扰要有效得多。
第7章 搭建组块对抗发懵 如何增进专业知识并减轻焦虑
发明只有在经过一段时间的考验后,人们才有机会发现它的不足,然后改进它。
不管你正在努力成为哪派高手,搭建组块过程打下的知识基础都可以助你一臂之力。
一旦你着手解决某个数学、科学问题,就会发现你做到的每个步骤,都会指示下一步的进行。
当你看一眼就能看出某题解法,即对题目有真正的了解,说明你已经成功构建出一个命令组块,它的命令就如一首歌在你脑中横扫而过。
搭建强大组块的步骤
1.全程在纸上解决一个重难点题目。在下手解题之前,或还没彻底得到答案之前,千万不能看答案,
2.重做一次,要格外注意关键步骤。
3.休息一下。
4.睡眠。在你睡觉前,把这个问题再过一遍。
5.再来一次。第二天尽快地把这个问题再做一遍。这个时候你会发现,自己能做到更迅速地解题。应该会有更深层次的理解。多关注问题中最困扰你的那个部分。这种持续关注难点的做法,叫作“刻意练习”。尽管这样做有时让人疲惫,但它是高效学习的最重要方面之一。
6.给自己添新题。再挑一道重难点题目,用之前做第一道题的相同方法来解这道题。本题答案会变成你组块资料库中的第二个组块。
7.“主动”重复。走去图书馆的路上,或是锻炼的时候,可以在头脑中回想解决某个题目的关键步骤。这种主动排演能提高你回想关键概念的能力,有助于在家庭作业或考试中回想要点。
这里用到的原理就是生成效应。相比单纯重复阅读,生成(即回想)材料可以帮助你更有效地学习。
要专注于学习解题步骤中最难的部分,并提高对这部分的解题速度。
已有研究表明,你越努力回想学习材料,它在记忆中植入得就越深。相比纯粹的重复阅读,回想才是学习过程中最好的刻意练习方式。
大师级玩家会花更多的时间来找出自身弱点并克服不足。
提取练习是最强效的学习方式之一。它的效果远超过简单地重读材料。
我们的记忆有个奇怪的特质,即主动重复比被动重复让人记忆更深刻。我是说,在以心记的方式学习的过程中(以此为例),等明白得差不多了,如果多花些时间和精力去回想,得到的效果比再看一遍书更好。
测试并不仅仅是衡量所学知识多少的手段。测试本身就是一种强效的学习经历。它可以改造你已有的知识体系或是为其添砖加瓦,同时可以显著地提高你记住学习材料的能力。
通过测试而发生的知识构成上的改善,被称为“测试效应”(testing effect)。它的发生多是因为测试进一步强化并稳固了大脑中的相关神经模型。
在学习期间做自我测试时,你还是想要尽可能地去获得反馈,并用参考书检查答案
读每一页时,试着概括出主要内容并铭记在心,然后翻到下一页。
工作记忆[从而也包括长期记忆(LTM)]中的组块“会随着练习和专业技能的增加而变大……组块也会随着长期记忆知识的变多而更加丰富,因为更多的长期记忆知识与每一个组块联系了起来,而且一些长期记忆组块还可以反过来与知识相连。最终,如果一个人成为专家,那么组块间存在的联结可以生成高层次的组块。
第8章 工具、建议和小技巧 最好用的学习应用和方法
我所知道的表现最出色的人,都在生活中运用了最好的小技巧
“改造”(reframe)自己的关注点。
能认识到运用正面思维技巧会增加个人优势,这是一种幸运。因为负面思维技巧,可能会让你做无用功,或是把简单问题复杂化。
“快人”毫不拖沓地把负面想法放在一边,对自己说,“别浪费时间了,现在就动手吧。只要你动手做事情,感觉就会好很多了”。
个人可以将每日活动计划详细记录下来,坚持一两个星期,了解自己拖延的症结所在。
要将遥远的目标分解转化为每日任务,一点点攻破难题。
·预防拖延的核心就是拥有合情合理的日计划和每周一次的周计划,它们可以保证你在宏观上保持前进步伐。
在前一天晚上写好第二天的计划。
第9章 拖延的小恶魔总结篇 你得和拖延症较较劲
习惯突击完成工作的人通常比那些合理安排时间、定时定量完成工作的人效率低很多。突击完成工作的时间如果太长,会让你精疲力竭。
够控制拖延的习惯,就意味着承认那些带来短暂痛苦的事情最终会是有益的。克服想要拖延的冲动与其他最终有益的小应激源具有很多共同点。
拖延有益的一面就是让你在急于完成某事之前学会“驻足与反馈”,学会明智地等待。
驻足与回顾不仅在克服拖延方面是关键,在解决数学和科学的问题时也是。
“驻足”给了你充足的时间去搜索自己的组块资料库,让你的大脑把这个具体的问题与宏观层面联系起来。
当你很难理解某个具体的数学或者科学概念时,重要的是不要让困惑控制你,让你觉得那些概念太难,或者很抽象而不去理会它们
在过去几十年里,盲目地跟随自己的激情,而非理性地分析职业选择是否明智的人,比起那些结合理性与激情选择工作的人,对自己的工作选择感到更不开心。
克服拖延症的方法:
·记行程日志。这样当你实现自己的目标之后,就可以回头追踪并了解哪些是有效的方法,哪些是无效的方法。
·每天都对自己承诺要完成一定的惯常事务和任务。
·在晚上睡觉前写下你计划的任务,这样你的大脑就有时间详细考虑你的目标,从而帮助你确保能够成功。
·把你的工作细化成一系列小挑战。
·要慎重选择时间,直到你完成了这个任务才能奖励自己。
·小心拖延的信号。
·让自己身处少有拖延信号干扰的新环境中
·障碍总会出现,但不要把你自己的问题全都归咎于外部因素。如果每件事都是别人的错,那就是时候好好审视一下自己了。
·相信自己的新时间系统。注意力集中的时候就要努力工作,该休息的时候要足够相信自己去休息,不要有负罪感。
第10章 增强你的记忆力 大脑虽小,空间无限
出于进化需要,这种“记住物体位置和样貌”的高级能力就固化在了记忆系统之中。
图像对记忆如此重要,部分原因在于图像与右脑的视觉中枢直接相连。[3]视觉区域有强化记忆的能力,图像让你充分利用这片区域,对看似乏味难记的概念进行压缩简化
通过激发感官建立起越多的神经联结,就越容易回想起概念和意义。
记忆宫殿法需要你回想一个你熟悉的空间,比如自己家的布局,然后把它当成视觉形象的记事本,用来存储你想要记住的概念形象。你要做的就是回想一个熟悉的空间:可以是你的家,可以是去学校的路,或是你最爱的餐馆。大功告成!眼睛一眨,这个空间就变成了你的记忆宫殿,用它就像用笔记本一样。记忆宫殿法对记忆互无关联的物品很管用
走进你的记忆宫殿,放好便于你记忆的图像。如果要记故事的五要素或科学研究方法七步骤等一连串信息,这种方法的帮助可就大了。
记忆法让你平时的学习更有意义、印象更深,也更有趣味。
来回踱步,甚至吃点提前准备的零食,都会对记忆有好处,因为脑力活动会消耗大量的能量
我们通过大脑的视觉皮层、听觉皮层、感觉皮层和运动皮层,分别记忆我们所见、所听、拿起或移动过的东西。
第11章 记忆技巧多多益善 打造生动形象的比喻或类比
在数学和科学的学习中,如果你除了想记住概念,还想理解概念,一个上策就是为它量身打造一个比喻或类比,而且,通常这个类比越形象,效果越好
类比(还有模型)之所以重要,是因为对数学和科学概念或过程背后的核心观点,它能让你获得直观形象的理解。有趣的是,比喻和类比在帮我们摆脱定式效应(我们之前提到过,指你困在一个错误的解决问题思路上)上也有不小功劳。
集中注意力能把一些东西送入临时性的工作记忆,但想让这个“东西”从工作记忆转移到长期记忆,有两个前提:它应当是便于记忆的,而且还要得到多次重复才行,否则,你的自然生理代谢过程就会像贪吃的小吸血鬼,把最新形成、还不明显的联结模型一扫而光。
记忆的另外一个关键就是创造意群,它能简化学习内容。
很多学科会有帮学生记住概念的背诵口诀。如果你是在背诵一些普遍为人所用的内容,完全可以去网上搜索一下,看是否有人已经想出了独特的记忆窍门
一定要警惕,分清楚什么是事实,而什么只是帮助记忆的比喻或类比。
别把上课就当上课,要把每节课看作有情节、人物和整体主旨的故事。
你的手脑之间有直接的联系,通过重写及梳理笔记,大量信息被分解为小而易懂的组块
在动笔之后,他们在接下来的学习板块中有了更好的表现
可别做一个方程写一百遍的傻事。头几次可能会有意义
如果你确实想让自己的记忆力和整体学习能力得到大幅提高,最好的办法之一就是进行体育锻炼。最近几项动物和人类的实验发现,规律的锻炼可以让记忆力和学习能力得到实质性的提升。锻炼似乎有助于促进记忆力相关脑区中新神经元的形成。锻炼也会生成新的信号通路,
锻炼似乎有助于促进记忆力相关脑区中新神经元的形成。锻炼也会生成新的信号通路,
不用文字而用思维图像来记忆事物,你能更轻松地达到专家水平。
小结
·比喻可以帮你更快地学会难懂的概念。
·重复是在记忆消退前对其进行巩固的必要动作。
·意群和口诀可以帮你简化学习内容,构成组块,这样就能更轻松地存储记忆了。
·编故事,哪怕故事听起来会有点笨拙,但它也会让学习内容更好记。
·写和说在一定上都有加强记忆的作用。
·体育锻炼对新的神经元生长、新联结形成有强大的促进作用。
第12章 学会自我欣赏 形成直观认识
不断重复会产生肌肉记忆,于是只要一个想法,即组块,就能让你的身体随之而动,而不必总要回想击球的所有复杂步骤
人们会试着理解他们感知到的信息。单纯听别人讲道理,是无法学会任何复杂概念的。正如数学老师所说:“数学可不是用来看着玩的。”
专家通常得在极短的时间内做出复杂的决定。这时他们会关闭自己的意识系统,转而依赖于久经磨炼的直觉,倾尽一切去利用根深蒂固的思维组块
在日积月累中,伴随着大量练习,才慢慢建立起自己的知识库的,他们在练习中形成了从宏观角度理解问题的能力。这样的练习把记忆痕迹牢牢储存在了长期记忆的仓库里,当你需要时就可以轻松快速地找到神经模型。
你的大脑中已经掌握的固有知识会阻碍你接受新的想法。超强的工作记忆会死死抓住原来的想法,导致新观念难以找到进入的空隙
越是聪明的人越容易在繁芜复杂的问题上迷失自我。而头脑略逊一筹的人反而更容易找到更简单的解决方法
拥有相对较小的工作记忆空间,意味着能更轻松地归纳学习内容,让新旧知识更有创意地结合在一起。
无论智力水平如何的象棋选手,都需要勤加练习来培养天赋。训练,尤其是对学习材料中最困难的部分更要刻意训练,这样才能让那些拥有普通智力的人有机会上升到“天赋异禀”的境界。
·“平均水平”的学生常常在主动性上、做好事情的能力上以及创造力上都有优势。
·把握创造力的一部分关键是要能从专注模式转换到更放松的、白日梦一般的发散模式。
·太过专注会阻碍你发现真正要找的答案
第13章 塑造你的大脑 改变思维,改变人生
卡哈尔认为他成功的关键在于毅力(“资质平平之辈的优秀品质”[2])、灵活的应变能力以及谦虚认错的态度。
卡哈尔认为,任何人甚至普通智力的人都能够塑造自己的大脑。这样即使是最没天赋的人也会有丰厚的收获。
似乎在他的自然成长过程中,经过自身对思维的培养,终于得以掌控自身的全部行为。
通过改变自身的思考方式,我们也能让大脑内部发生显著变化。
快速学习数学和科学的关键,是要意识到每个所学概念几乎都可以与你已有的知识进行类比,这就是做比较。
·在科学、数学、技术领域取得成功的专业人士,逐渐习得的一个特质,就是学会如何组块——提炼关键思想。
·比喻或实体类比也能构造组块,这些组块能使一个截然不同的领域的概念对另一个领域产生影响。
第14章 借方程的诗歌打开心灵之眼 解开标准方程下每一句话的含义
思想能表现为语言就能表现为形象。
努力学习数学和科学的时候,我们能做的最重要的一件事,就是给脑中的抽象概念赋予生命。
费曼法,这个方法要求人们找到简单的比喻或类比来帮助他们理解概念要旨。
迁移是把所学的知识从一个知识背景应用到别处的能力。
迁移的好处在于,随着一门学科内容难度的增进,迁移往往能让学生学得轻松一些。
·你的“心灵之眼”之所以重要,是因为它帮你在脑中排演,并把学过的知识拟人化。
·在学习过程中一心多用会让学习无法深入,这样会限制你迁移所学知识的能力。
第15章 学习的复兴 自学的价值
比智力更重要的往往是毅力。以自学为目标去接触学习材料,能让你以仅有的方式从入门走向精通。
只有学生自己主动参与课题,而非仅听他人言传,才能取得最好的学习效果。一个学生要能靠自己剖析学习材料,且偶尔从同学那得到反馈,才是关键。
要训练自己克服“囫囵吞枣”的学习阶段,并迫使自己直击问题真正要害,而不是借机会向老师炫耀自己学过什么。
一般来说,最好的做法是重新梳理思路,然后听听老师的建议。当你最终明白了答案,就可以回头纠正你以前犯过的错误。
失败是更好的老师,它会让你反思自己的学习方式。
·自主学习是一种最深入、最有效的学习方式:
·自主学习能够提高你独立思考的能力;
·在学习中,毅力往往比智力更重要。
·人人都是既有竞争意识又有合作意识。总是会有人批评或低估所有你付出的努力,你要学着对这些问题淡然处之。
第16章 避免自负 团队合作的力量
右脑的任务就是扮演魔鬼代言人的角色,不停地质疑现状寻找矛盾;而左脑则坚持事物原本的样子。
当你万分肯定自己完成的作业或试卷没有问题时,不好意思,这可能是过度自信的观点,由左脑产生。
第一准则就是你不能自己欺骗自己,因为自己是世界上最容易被骗的人。
波尔清楚,只要对方有所见解,与人合作、集思广益都会有所帮助。凭借个人的努力分析工作,无论是两种模式还是左右脑,都难免会有不足。毕竟,每个人都有盲区。
乐观的专注模式会本能地跳过错误,尤其是错误本来就是你自己造成的时候。
和朋友一起学习能让你更容易看出自己哪里理解有偏差。
你的熟人数量,而非好友数量,保证了你能得知的最新信息以及工作中的成功。
团队学习对数学、科学和工程等科技类学科非常有效。
·即使你自信一切没有任何问题,专注模式还是会让你不经意地犯下致命的错误。温故知新,不同的神经活动过程可以让你重新审视结果,抓出错误。
·学习中的批评,无论你是批评者还是被批评者,都应该客观对待。它们是在帮助你理解所处理的问题。
第17章 参加考试 考试本身就是效果非凡的学习经历
考试本身就是一种效果非凡的学习经历。似乎考试有让人精神集中的美妙效果。
备考检查清单(你记下的回答中“是”越多,说明你复习得越好。如果你的回答里有两个及以上的“否”,那你可能要认真考虑在下次考试前改变一下复习策略。)
1.你有没有尽力去理解课本内容?(带着目的去找相关例题不算在内。)
2.你是否有跟同学一同解决作业问题,或者至少跟他们核对过答案?
3.你在跟同学合作之前,有没有先试着自己大致写出每道题的解法?
4.你是否积极地参与了家庭作业的小组讨论(贡献点子,提出问题)?
5.当你遇到困难的时候,有没有请教老师或助教?
6.你交作业的时候,是否完全理解了所有问题的答案?
7.当不明白家庭作业的题目解法时,你有没有在课上提问寻求解释?
8.如果你有学习指导手册,你有在考试前仔细通读过一遍吗?确定手册上的所有题目都会做了吗?
9.你有没有试过快速列出解题纲要,而不在基础计算上花时间?
10.你是否有和同学一起复习过学习指导手册和问题,并互相提问?
11.如果考前有复习课,你是否参加过,并在课上提出任何你不太确定的问题?
12.你在考前有没有保证合理的睡眠?(如果这个问题的答案是“否”的话,那前面1~11的答案可能都不重要了。)
试卷一发下来,先快速浏览一遍,对试卷内容有个大致印象。(对任何考试你都应该这么做。)放眼去找看起来最难的题目。
开始做题时,就先做看起来最难的那道。不过要做好准备,一旦你发现自己已经一两分钟没有进展,或者感觉可能想偏了,就要立刻抽身出来。
忧虑的作用有好有坏。适当的忧虑能赋予你动力,帮你集中注意力,而不当的忧虑只会浪费精力。
由难入简法通过让大脑各个部分同时处理不同的想法,来提高大脑的利用效率。
在考试中运用由难入简法,能够保证你至少每道题都做上一点。这种方法也能有效防止你陷入思维定式,即一直在错误的思路中徘徊不前,因为这个方法会让你有机会多次多角度审视问题。这个方法唯一的难度在于,一旦你发现已经过去了一两分钟却仍止步不前,就必须足够自觉地从这道题目中抽身。
对于考试恐慌人群来说,还有一个好建议就是把注意力暂时转移到自己的呼吸上来。你要是能提前几周开始练习,每天随意花上一两分钟就足够了,到考试的时候,你就能更加轻易地进入这种呼吸模式。(要记住,常练不忘!)
为什么考试中最难的题目等最后才做会造成麻烦。因为当你所剩时间越来越少,压力会越来越大,却恰恰还面临着最难的题目。
消极的自言自语,即你的脑海中产生的负面念头,确实会影响到你的表现,所以一定要保证让积极的言语和内心想法贯穿整个备考过程。
在学习中进行自我测试是把知识印在脑海里的绝佳办法,这样等你到了考场的高压环境下,能更容易回忆起这些知识
学会在动手做题前或遇到障碍时停顿几秒,会有助于你看清解题思路
第18章 释放无限潜力 学习的10个好方法和10个误区
伟大的艺术家、科学家、工程师还有像马格努斯·卡尔森这样的象棋大师,首先靠集中注意力利用他们大脑的自然节奏,努力在脑中思考问题,之后再将注意力转向别处。这种在专注和发散模式下交替思考的方法,能让思维的云朵更容易漂移到大脑的新领域。最终,这一片片云朵,经过再提炼、再蓬松,就能为你带回一部分有用的解题思路。
大脑的重塑由你掌握。重塑的关键在于坚持不懈——明智地对待你大脑的优势和弱点。
要提升专注力,你只需从容地重新定向自己对干扰信号的反应,比如手机铃声或短信提示音。
在专注工作期间搭配着有规律的放松,不仅能让我们在学习中获得更多的乐趣,还能学得更加深入。
对掌握数学和科学至关重要的一点,是要让透彻理解的组块成为自己根深蒂固且久经磨炼的一部分。
学生如果在学习数学和科学的过程中拖拖拉拉,他们也不能培养出固化的神经组块。
世界上最擅长思考的人长久以来在用的一个窍门就是简化——用小孩子都能听懂的语言解释事物。
10个好的学习法则
1.运用回想。读完一页书,看向别处并回想主要观点。
2.自我测试。任何内容皆可测试。
3.对问题进行组块。搭建组块的过程就是理解问题、练习解题方法的过程,有了组块才能在脑中瞬间闪现答案。
4.间隔开重复动作。无论学哪门课,不要安排得太集中,要像运动员一样每天安排些练习量。
5.在练习中交替使用不同解题技巧。做任何练习的期间不要只用一种解题技巧。解题方法要混合使用在不同的题型上。(用手书写比起打字时构建的神经结构更坚实。)
6.注意休息。每天学一点,比集中在一天学会好很多。
7.使用解释性的提问和简单类比。怎样解释才能让10岁小孩都明白这个概念?使用类比真的有用
8.专注。关掉手机和电脑上所有会干扰你的提示音和闹铃,并在计时器上设定25分钟。你要在25分钟之内集中注意力,并尽可能勤奋工作。
9.困难的事情最先做。最清醒的时候,要去做一天中最困难的事情。
10.心理对照。想象过去的你,对比通过学习能够成就的那个自己。
10个坏的学习法则
1.被动重复阅读。很被动地坐着看书,目光再次扫过书页上看过的内容。
2.满眼尽是重点标记。
3.瞟一眼解题方法,就觉得胸有成竹。这是学生学习时所犯的最糟糕的一个错误。你要做到的,是不看答案也能一步步解决问题。
4.等到火烧眉毛才开始学习。
5.已经清楚解法,但仍反复解答同一题型。
6.与朋友一起把学习变成了闲聊。
7.做题前忽视读课本。
8.有疑问点,却不找导师或同学核对并解决。
9.时常分心,却还以为自己能学得足够深入。
10.睡眠不足。睡眠中,你的大脑会将解题技巧拼凑在一起,同时它也会对你睡前习得的任何内容进行反复练习。长时间的疲劳会让毒素在脑中堆积,毒素会破坏神经连接,
书中提及的图书
《重新定向》(Redirect),作者是心理学教授Timothy Wilson,书中描述了“失败到成功的故事”的深远意义
史蒂文·约翰逊(Steven Johnson) 《好想法从何而来》
尼尔·菲奥里(Neil Fiore) 《战胜拖拉》(The Now Habit)
约书亚·福尔关于演示记忆宫殿法如何记住演讲词的大师级TED演讲 http://www.ted.com/talks/joshua_foer_feats_of_memory_anyone_can_do.html
记住公式,试试进SkillsToolbox.com这个网站去找一些表征数学符号的图像资料
记忆宫殿
西尔瓦诺斯·汤普森(Silvanus Thompson)《轻松学习微积分》(Calculus Made Easy)
SQ3R学习的每个要素(有时是SQ4R——浏览、提问、阅读、背诵、复习和书写)
罗宾·艾伦(Robin Aaron) 《提高你的物理成绩》(Improve Your Physics Grade)
William James 《与老师谈心理学》
《知无涯者:拉马努金传》(The Man Who Knew Infinity:A Life of the Genius Ramanujan),罗伯特·卡尼格尔著
《高贵的野蛮人》(Noble Savages),拿破仑·夏侬著
《数学大师》(Men of Mathematics),E.T.贝尔著。














