本文简单粗暴地分为五部分:
一、财报数据不理想及原因拆解。
二、不理想的状态还会持续多久?
三、当前价格很超值。
四、我的计划。
五、具有关注价值的八个细节。
下面逐条聊。











转自:https://mp.weixin.qq.com/s/EcwItD-x4Py24ZYvureubw
分享个人经验,保留阅读记录,做时间的朋友
本文简单粗暴地分为五部分:
一、财报数据不理想及原因拆解。
二、不理想的状态还会持续多久?
三、当前价格很超值。
四、我的计划。
五、具有关注价值的八个细节。
下面逐条聊。
转自:https://mp.weixin.qq.com/s/EcwItD-x4Py24ZYvureubw
兔主席 20220315
中国内地这一波疫情由外部输入引发,迄今已有大概一万五千病例,在吉林、山东、上海、广东、河北等多省市爆发,一些城市处于“准封城”或“类封城”状态,跨区域旅行很多受到限制,对各行各业的人们生活都有影响。2020年初,中国经过几个月的时间平复疫情,2021年基本克服了疫情的影响。到2022年的现在,疫情已经两年了,人们对大规模的防疫行动已经呈现明显的疲惫,不知道何时这一切才能终结。今年还提出增长率5.5%的要求,疫情因素的加入也使得经济面临更大的不确定性。这还要配合新发展模式、新政治经济范式下许多行业的重组。许多人都是很焦虑的。
特别是,外国所呈现的“一切恢复正常”、“走出疫情”的那种态势,更让国人焦虑——我们未来的路如何?
中国人是既要又要的矛盾体。
一方面,中国社会对大规模病死是没有准备的:没有心理准备、社会准备、经济准备、政治准备。香港这一波疫情是对我们的一个“提醒”:这一波目前确诊人数约75万(实际上染病人数则可能是百万级甚至数百万级别的),死亡人数4,355人(早已超过武汉的3,800多人),全港已经出现“棺材荒”。
这里。我们算一算“大数”,仅仅做一个匡算。自2021年12月31日到本文写作时,香港病死4,355人的话,就是大概每个月去世1700人。香港人口700万,中国内地人口14亿,是香港的200倍。简单匡算,假设所有地方的医疗条件与香港一样,防疫的客观基础也一样(例如老人疫苗接种率类似),并简单假设全国同时密集爆发,则1,700 x 200 = 每个月死亡34万人,两个半月就是87万人。中国能够承受这个死亡人数么?
再看美国。截至目前,美国官方公布的感染数是7,950万,累积病死96万人。比照美国的医疗基础,尚且要死近100万人,中国的人口数量是美国的四倍,那掐指一算,即便我们和美国的医疗水平一样,也得死400万人。如果我们承认全国范围的基础条件弱于美国(正如我们的人均GDP也仅是美国的四分之一),那中国可能死亡1,000万人,甚至更多。中国能够承受这个病亡人数么?
显然是不行的。一旦出现大规模疫情及病死,中国社会就会崩溃,造成巨大的经济、社会及政治不稳定。
现在,很少人会去考虑这种可能性,因为似乎已经“理所当然”了,难以想象。人们也很难直观“感受”到400万人、1000万人的生命得到保护的那种“收获”、“好处”、“福利”。在坐享疫情防控带来的保护及好处之余,只会感染嫌公交车停运麻烦,核酸检测麻烦,差旅出行麻烦,不能出国等等。
大规模疫情爆发,真的出现了病死,那就是我们身边的家人出现病死。每个人不仅都有感染的朋友,而且还有死去亲人的朋友。那时对经济社会的影响会是巨大的:无数的人染病,或者因为照顾染病的家人而无法正常工作。你再无法到医院去看病,因为人满为患。你会发现日常生活大受影响,围绕你生活的各行各业都有人受到影响,譬如,你可能突然发现快递收不到了,因为管你的小区的外卖小哥家里有人重病甚至去世,他要回老家照顾或办理后事。这只是一个小的例子,并不是说你始终收不到快递,而是说,这样的冲击、死亡会成为生活的一部分。中国作为全球制造业、供应链、产业链的基础地位也会受到打击。我们能不能与病毒“共存”呢?可以,请先付出数百万、上千万人死亡的代价,踏着尸体,“涅槃重生”。
这个根本就不是一个选择。到那个时候,不仅仅是社会问题,政治稳定都会受到影响。
那些在朋友圈上抱怨疫情防控政策的人,都会成为体制的批评者。
经历了2020年2-3月中国舆情的人,应该知道这种全社会性的负能量有多可怕。
所以其实中国在初始道路上是没有选择的。我们的路线是正确的,符合中国的国情。
现在的问题只在于:下一步怎么办。What next。是的,全世界都为COVID-19付出了代价,每个国家都死了很多人,都是付出了生命的代价,才走到这一步的。中国之前确实表现得很好,但我们也总不能永久这样下去吧?
这也是世卫组织思考的问题。何时大COVID从“pandemic(大流行病/瘟疫)”降格为“endemic(流行病),如何降格防疫管控指导建议,让社会回复常态。
对这个问题是有答案的。笔者之前写过,需要满足若干条件。
第一,我们(中国)要独立地、从科学上确立:
1)Omicron是一个弱化的变种,致死率、危害性是减弱的
2)Omicron是一个在进化生物学里“优胜”的变种,“统一”了天下,不太可能再出现一个强化的变种取代它
3)对于大多数人口来说,Omicron甚至是一种“活体疫苗”——特别对于已经打了疫苗的人来说——它有利于推动所谓的“群体免疫”
4)没有压倒性的证据说明其对广大人口会产生重大的后遗症(即所谓的“Long Covid”),且这种后遗症会转化成为巨大的人口、生理、健康、社会乃成本——尤其是那些打了疫苗后仍被感染的无症状感染者或轻症患者。这里,是无法回避权衡分析的(a cost-benefit, utilitarian analysis)
第二,国际国内科学界、公共卫生决策群体对上述看法要形成大致共识——并不是说每个人都要同意,只要主流。
第三,我们要确立目前完成大规模接种的国产灭活疫苗对Omicron的保护性(主要为重症,包括住院及病死)。这方面,有关部门已经可以收集到大量信息,包括我国在海外广泛出口疫苗的地区,及在香港特别行政区。今年2月10日,港大有个报告,说明科兴三针对重症的保护率为80%,病死为90%。是一个参考(https://sph.hku.hk/en/News-And-Events/Press-Releases/2022/TBC)。在对疫苗建立了充分信心后,就可以向前迈进
第四,世界各国加地区的确诊及病死不断降低——伴随各国在“疫苗+自然感染”作用下,陆续进入“群体免疫”,感染数是一定会下降的。中国防疫管控政策如果要向前迈进,一定需要选择这样的时机。
第五,世卫组织表达出意向,打算对COVID-19的防疫管控指导宽松化。根据中国政府的负责任的做事风格,应当也会与WHO充分沟通。
第六,涉关14亿人的大事,而且开弓没有回头箭,从中央到地方的有关部门,公共卫生专家及医学专家,要进行必要的研讨,论证是否存在任何没有想到的议题、短板,或其他考虑不周的地方。需要反复再三论证,反复斟酌,不能挂一漏万。
第七,综合多个考量角度,基本能够确立:调整防疫模式所获的综合“收益”显著大于其“成本”。不同防疫模式优劣比较的天平发生实质改变,朝“宽松”模式的一端偏移。
第八,要做足宣传、教育、舆论方面的准备。中国的国民,说容易管理,也容易管理;说不容易管理,也不容易管理,因为他们“既要又要”,既希望享受放开的好处,但又担心疫情/疫病的成本和影响。而这是一个把发烧都看得很严重、动不动就要跑医院的社会,对呼吸道传染病是缺乏充分准备的,而中国在最初就把新冠等同于肺炎(或SARS),使得大多公众对COVID-19仍然十分恐惧。除此之外,人们对目前的政策也不理解,以为不敢放开就说明疫苗无效。所以,要向国民做好宣传教育,是需要的大量的准备与工作的。
第九,中国改变现有防疫模式,绝对不可能是一步到位的,一定是个有序、逐步的过程,能收能放,可进可退,留有充分余地,而不能开弓没有回头箭。这就是笔者之前说的极具中国特色的“试点模式”——在一地打开,成功后在异地复制,最后全国打开。《COVID-19:抗疫的回顾与未来》
香港的第五波疫情,以及内地这一波爆发(两者有很大的关联性),实际上又给中国进一步调整防疫模式提供了宝贵的经验及“演练”的机会,补充了之前可能存在的一些盲点或考虑不周的地方。
未来,有可能如何推进试点放开呢?
第一,中国内地应当处在一个疫情基本被控制,大致“清零”(当然不一定是绝对清零)的状态。其实,这就是今年以来香港第五波疫情爆发之前中国内地的状态。处在这个状态,首先要复归这个状态,才能迈向下一步。所以中央会下定决心,提出比较严格的防疫政策,用一到两个月的时间在全国(内地)范围内把疫情控制住。这是一切的前提。
第二,选择一个合适的省份或地区进行试点。这个地方的先天条件:
1)具有一定数量的人口,比如至少是千万级
2)人口结构有一定的代表性
3)离内地的政治、经济中心有一定的地理距离
4)不属于边陲/边境少数民族地区(政治敏感)
5)如有一定的天然物理隔离最好,因此,理论上应该避免选择内陆中心省份或地方
6)作为试点放开后,可以获得比较多的经济及社会收益(外向型经济)
大家可以看到,这和我们选择经济特区的标准差不多,要参考自然资源禀赋。
第三、要有充分的防疫基础
1)全社会三针疫苗接种率达到较高水平(门槛可以具体设立)
2)重点人群(如老人)三针疫苗接种率达到绝对高水平,例如90%、95%、98%……
3)要有一定的医疗基础设施及资源作为前提基础,从社区医疗站、医院、医护人员,到病床及ICU、医疗设备、药品等
4)提前建立好一定容量的方舱医院
5)有统一的援助电话热线,提供统一的医疗指导与建议,避免挤兑线下资源
6)要有充分的COVID-19相关教育宣传
——要建立并能依赖居民自检能力:自己购买抗原及核酸检测工具并自行测试
——看到Omicron-COVID-19并不简单等于“肺炎”(新冠的认知概念“去肺炎化”)
——要建立普遍意识:确诊后居家自愈,轻症不上医院,避免挤兑医疗资源
——对如何自愈要有广泛的宣传教育
——基层治理/网格化管理:对社区/街道/居住区物业人员提供必要的培训——他们将成为后续提供支援的重要力量——只不过,这一次他们也要有观念上的转变。
7)建立摸底了解实际感染及致病情况的机制,例如定期做人口抗原测试,做大规模的调研、考察、访谈,了解病毒的实际影响
第四、地方工作需由中央牵头/参与。
目前机制下,防疫、抗疫是地方官员头等大政治。工作做得不好,是要丢乌纱帽的,所以如果主动选择的话,地方可能不愿参加试点。因此:
1)由中央指定地方试点,和当年搞经济特区一样。这个得自上而下、全国一盘棋考虑,至少在一开始,不能依赖地方自主申请
2)中央工作组到地方牵头协调工作,承担地方所不能或不愿承担的政治责任。这样:
——地方/基层有了政治保证,才能放弃顾虑,全力配合
——中央有更大的政治权能/授权,可以帮助协调地方不能协调的事项及资源
——对当地人的体验也会更好:让他们感受到,这既代表了中央政府和全国人民给予他们的信任、责任,是一种为历史铭记的壮举,也让他们有安全感和温暖感(不是什么“小白鼠”),甚至认为自己享受到了某种先学一步的特权和好处
3)由中央安排对地方提供必要的财政支持
第五、对当地的“温馨安排”
1)试点要“事前通知”这个政策一定要做好重组的事前准备、铺垫,到了宣布的时候,也要提前告诉地方,比如说,提前两个月,这样,可以让当地人做一些选择安排,不愿意参与的人可以用脚投票,离开当地
2)给当地人适当的补贴或激励,从个人到机构、企业,譬如医疗上的、税收上的,甚至直接的财务刺激/物质补偿。总之,可以让他们有一些获得感。毕竟他们是付出了代价的——至少和国内其他地方通行/通航不再方便
第六、要有充分的援助机制
在最初,就建立好对试点省份/地区的援助机制,包括医护人员、医疗设备、药品等,以及增建方舱医院的能力等。提前部署。
第七、与其他省份建立好隔离机制
1)试点省份,一旦打开,与其他国家就不需要有严苛的隔离限制了,或者说只留有非常宽松的隔离限制,这可以比照新加坡之类的地方。
2)但反过来,试点省份与中国内地其他地方,就需要建立隔离机制了。凡从试点省份进入内地省份,需要做隔离。这可能是当地人要承担的最大成本。对于试点省份,国家可以考虑补贴旅行人员的隔离成本。经济账是小事,最后算的是政治账。
3)要为试点省份建立一套数据化的通行卡,并更新现有的行程卡/各地健康码,可以识别、记录、追踪试点省份的人员。这里,宣传教育非常重要:不能对试点省份人员有任何歧视。
第八、逐步打开 + 熔断机制 + 试点省份连成一片
这是一个循序渐进的过程。
1)先让试点省份运行一段时间,如果疫情严重,无法对抗,则立即“熔断”,重新封城/省,退回重来
2)试点省份与内地其他省份/地区的人员通航需要遵循内地对待境外人员的隔离标准
3)如果试点省份向内地其他地区输入了确诊病例,则需采取必要的熔断措施(标准和方式可以具体确定)。这里,一定要参考香港的经验
4)如果发现试点省份能够比较成功地应对COVID-19,那么就可以扩大试点省份。具体,可以由中央自上而下安排,也可以由各地自主申请,但无论如何,参与试点的省份应该满足中央拟定的必要的防疫软硬件指标。
5)试点省份之间可以连成一片,放宽或放弃隔离要求。
6)星星之火,可以燎原。试点省份点点相连,连成一片,有朝一日就可以遍及全国。当过半数的中国省份加入试点后,“新循环”就形成了。剩余的省份将争相提升防疫软硬件指标,参与“新循环”。
7)过程中,只要有任何不可控的负面因素,就做“收缩”。最坏情况就是“恢复原状”。这就是“可放可收”。
中国希望完成的,是通过几年时间,最终安然度过COVID-19,付出的是全球人类社会里最低的病死人数。这将是一个历史性的胜利。
笔者以为,也只有中国有可能成就这样的胜利,得益于中国特色的制度与模式。它不仅仅对COVID-19有启示,还将对人类未来对抗病毒及(超级)病菌的及其他重大国际问题都有启示。
上面描写的试点放开机制,何时可以推行呢?
还是回到第一个前提,先“动态清零”,在中国内地大多省份城市“复归原状”,然后再谈逐步改变模式。以笔者对中国体制的理解,今年还是一个清零和准备的阶段,可能需要等到明年。
以上是笔者自己猜想的,基于中国国情及制度逻辑推理的下一步演进可能。抛砖引玉,仅供参考。
(全文结束)
转自:https://mp.weixin.qq.com/s/K4SoFVlRrgBgKTAxewm4eA
昨天(3月25日),上海市正式发布《2022年高中阶段学校招生工作的若干意见》。(详情:重磅!2022年上海中考招生细则发布!“中招录取”分三个批次进行!)
根据中考招生实施细则,名额分配综合评价录取的总分由学业考试总成绩和综合考查成绩两部分构成。录取顺序依次为:(1)“名额分配到区”录取;(2)“名额分配到校”录取。“名额分配到区”和“名额分配到校”综合考查入围末位同分时,按末位同分同投入围。
那么,究竟每所初中能获得多少名额,今天我们帮大家推演一下。
委属市重点名额分配
今年开始,委属市重点(四校)名额分配,按照如下原则:
四校名额分配,占四校招生名额总数的65%。
四校到校名额为20%,也就是65%X20%;四校到区名额是80%,就是65%X80%。
我们以2021年四校招生人数为依据(仅供参考),按照新中考招生名额分配方案,推算一下四校的分配数量。
公式:名额分配数量=2021年招生总人数×65%
上中:分配名额数量为385*65%=250人
华二:分配名额数量为380*65%=247人
复附:分配名额数量为361*65%=235人
交附:分配名额数量为398*65%=259人

委属市重点名额到校数量较少,我们就不分拆了,有兴趣的家长可以按照公式计算一下。
以上海人口大区——浦东新区为例:2021年,浦东中招人数除以上海总中招人数,得出的比例为25.02%。
经计算,浦东新区能拿到四校共248人的分配名额,这样的名额分配数还是很可观的。
浦东、闵行、松江较为领先,部分偏远地区能拿到的名额甚至都超过了徐汇、杨浦、黄浦、长宁。
这是由于这些区总人数少,参加中考的人数就少,导致能拿到的四校名额也较少。
区属市重点名额分配
和委属市重点65%占比不同,区属市重点名额分配的占比为60%。
我们根据2020年区属市重点高中的招生计划,为大家推算一下16区初中名额分配到校数量:

通过上表可以看出,各区初中都能够分配到3个以上区属市重点高中的名额,大部分初中普遍都在5个以上名额。
特别是黄浦区,每所初中可以分配到23个区属市重点高中名额,换句话来说,在黄浦区读初中,只有能考取学校的前23名,就可以进区属市重点高中,这个比例是非常高的。
接下来,我们根据2020年中考推荐生7%倒推中考人数,计算出各区各初中名额分配到校人数:
徐汇区

浦东新区


初中学校人数:来源于2020年浦东体育考试名单
上实、浦外为择生源学校,无名额分配到校资格
上科大附属、未来科技等学校没有毕业生,暂未列入
宝山区

民办初中人数:2021年招生计划
公办初中人数:2021年初中在校生人数推算
由于华二宝山名额分配到校仅25个,小于本区初中学校数量,将随机分配。
虹口区

上外附中、上外附中东校属于选择生源的学校,无名额分配到校资格。
黄浦区

康德双语实验等学校暂未有毕业生,不列入。
杨浦区

初中学校人数:按照2020年杨浦二模人数计算
长宁区

市三女中仅招收女生,名额分配方式未知。
嘉定区

初中学校人数:按照2020年嘉定历史考人数
静安区

奉贤区

金山区

闵行区

普陀区

青浦区

松江区

崇明区

其中青浦中学、朱家角中学、松江一中、松江二中、奉贤中学、崇明中学由于缺失名额分配以及平行志愿数据所以青浦、奉贤、松江、青浦四个区的数据未展示。
本文采用2020年中考相关数据,具体情况请根据当年中考情况判定,仅供参考!
最后说几句:
2022年新中考改革,各区名额分配到校的比例都大幅上升了,更加注重了区内教育资源的覆盖,均衡了各区市重点的发展。
注:本文数据为准演结果,不代表最终的实际情况,具体安排以官方为准。
转自:https://mp.weixin.qq.com/s/KE18caauNUNLgBgS2cho6w
基于市场非有效或弱有效的理论基础之上
定量投资正是在找估值洼地,通过全面、系统性的扫描捕捉错误定价、错误估值带来的机会。
统计套利是利用证券价格的历史统计规律进行套利,是一种风险套利
一类是利用股票的收益率序列建模,目标是在组合的Beta值等于零的前提下实现Alpha收益,我们称之为Beta中性策略。
另一类是利用股票价格序列的协整关系建模,我们称之为协整策略。
算法交易分为被动型算法交易、主动型算法交易、综合型算法交易三大类
建议读者使用已有的类库解决问题而不是自行编写相应的代码
数据处理的最终目的就是使用不同的特征属性对目标进行区分和计算。已有的目标是观察和记录的结果,而数据处理的过程就是创建一个可进行目标识别的模型的过程。
建立模型的过程称为数据处理的训练过程,其速度和正确率主要取决于算法的选择,而算法是目标和属性之间建立某种一一对应关系的过程。
当数据处理建模的最终目标是求得一个具体数值时,即目标是一个数字,那么数据处理建模的过程基本上可以被转化为回归问题,差别在于是逻辑回归还是线性回归。
对于目标为布尔型变量时,问题大多数被称为分类问题,而常用的建模方法是决策树方法。一般来说,当分类的目标是两个的时候,问题被转化为二元分类;而分类的结果多于两个的时候,分类称为多元分类。
数据处理的数据往往来自于现实社会,因此可能数据集中大多数的数据都会有某些特征属性缺失,而解决的办法往往是采用均值或者与目标数据近似的数据特征属性替代。
NumPy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效得多
计算数据集的和、均值、标准差以及方差
print(np.sum(col1))
print(np.mean(col1))
print(np.std(col1))
print(np.var(col1))
图形化数据处理——Matplotlib包的使用
$pip install pylab
$pip install scipy
$pip install matplotlib
画图
import numpy as np
import scipy.stats as stats
import matplotlib.pylab as pylab
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False],
[4,116,70.8,1,False],[5,270,150,4,True]])
col1 = []
for row in data:
print(row)
col1.append(row[0, 1])
stats.probplot(col1, plot=pylab)
pylab.show()
scipy是专门进行数据处理的数据处理包,probplot计算了col1数据集中数据在正态分布下的偏离程度。
不同的属性对于数据处理来说,需要一个统一的度量进行计算,即需要对其相似度进行计算。常用的两种,即欧几里得相似度计算和余弦相似度计算
欧几里得距离(Euclidean Distance)是最常用的计算距离的公式,它用来表示三维空间中两个点的真实距离。欧几里得相似度计算是一种基于用户之间直线距离的计算方式。在相似度计算中,不同的物品或者用户可以将其定义为不同的坐标点,而将特定目标定位为坐标原点。使用欧几里得距离计算两个点之间的绝对距离。
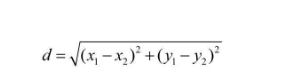
欧几里得的计算数值与最终的相似度计算成反比,欧氏距离越小,两组数据相似度就越大,欧氏距离越大,两组数据相似度就越小。因此,在实际中往往使用欧几里得距离的倒数作为相似度计算的近似值,即使用1/(d+1)作为近似值。
与欧几里得距离相类似,余弦相似度也将特定目标(物品或者用户)作为坐标上的点,但不是坐标原点,与特定的计算目标进行夹角计算
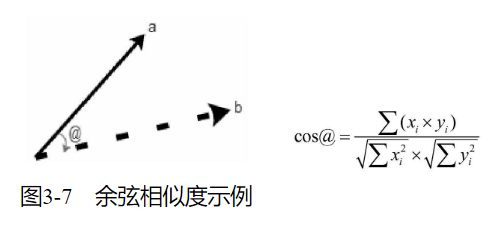
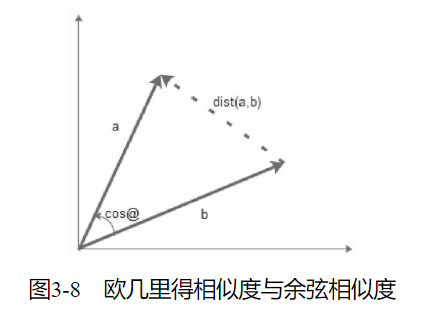
欧几里得相似度以目标绝对距离作为衡量的标准,而余弦相似度以目标差异的大小作为衡量标准。欧几里得相似度注重目标之间的差异,与目标在空间中的位置直接相关。而余弦相似度是不同目标在空间中的夹角,更加表现在前进趋势上的差异。
欧几里得相似度用以表现不同目标的绝对差异性,从而分析目标之间的相似度与差异情况。而余弦相似度更多的是对目标从方向趋势上区分,对特定坐标数字不敏感。
在分析用户相似度时,更多的是使用欧几里得相似度而不是余弦相似度对其进行计算。余弦相似度更好地区分了用户的分离状态。
四分位图是一个以更好、更直观的方式来识别数据中异常值的方法,比起数据处理的其他方式,它能够更有效地让分析人员判断离群值。
数据的标准化是将数据根据自身一定比例进行处理,使之落入一个小的特定区间,一般为(-1,1)之间。目的是去除数据的单位限制,将其转化为无量纲的纯数值,使得不同单位或量级的指标能够进行比较和加权,其中最常用的就是0-1标准化(0-1 normalization)和Z-score标准化(zero-mean normalization)。
0-1标准化也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间
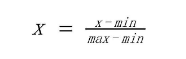
Z-score标准化也叫标准差标准化,经过处理的数据符合标准正态分布,即均值为0,标准差为1
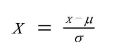
μ为所有样本数据的均值,σ为所有样本数据的标准差。
对于每种单独的数据属性来说,可以通过数据的四分位法进行处理、查找和寻找离群值,从而对其进行分析处理。但是对于属性之间的横向比较,每个目标行属性之间的比较,使用四分位法则较难判断
平行坐标(Parallel Coordinates)是一种常用的可视化方法,用于对高维几何和多元数据进行可视化。
热点图是一种判断属性相关性的常用方法,根据不同目标行数据对应的数据相关性进行检测。
使用掘金量化相比较其他平台的好处在于,可以使用Python IDE编辑器进行数据处理和编辑,并通过掘金终端获取回测结果。
手动下载SDK
$ python.exe -m pip install gm -i https://pypi.doubanio.com/simple
点击我的策略可查看回测记录

点击可查看详情
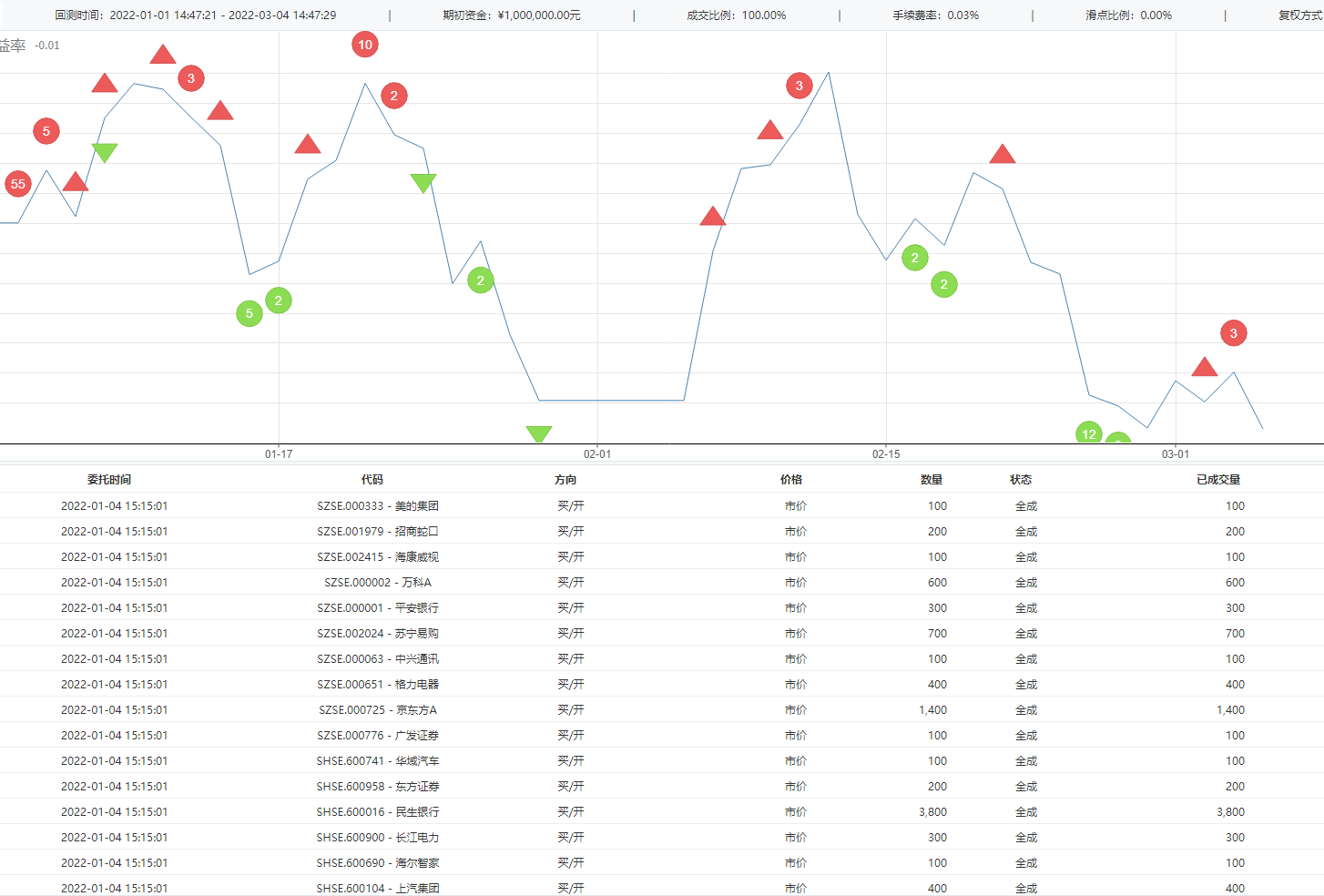
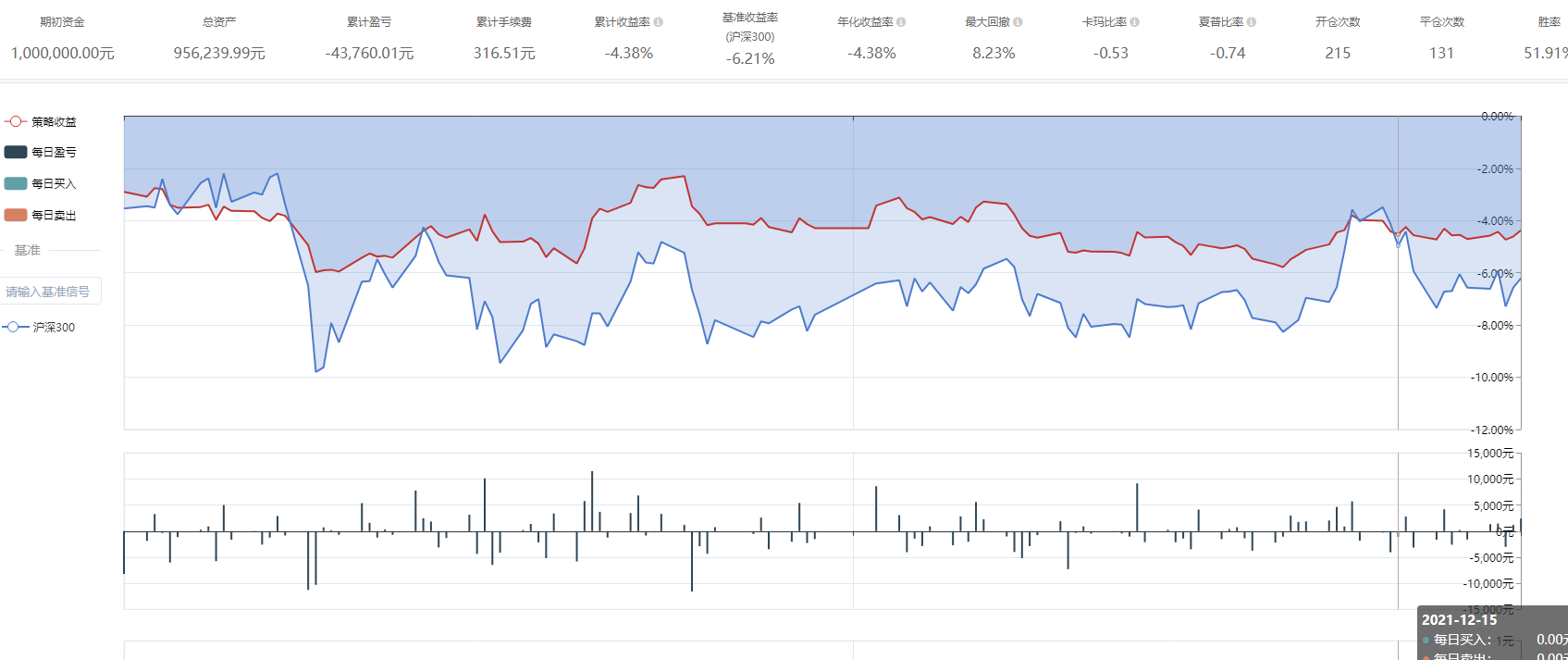
这玩意好像不怎么灵光啊,一年亏3,4个点,略好于指数
官网称其为TA-Lib 技术分析库,是一种以Python为基础的广泛用于量化交易中对金融市场数据进行分析的函数库。Technical Analysis Library,主要功能是计算行情数据的技术分析指标,用来开发技术分析策略
https://pypi.org/project/TA-Lib/
忽略一下这个不知道哪一家的 文档:https://technical-analysis-library-in-python.readthedocs.io/en/latest/
安装 :pip install TA-Lib
https://github.com/mrjbq7/ta-lib
安装
Download ta-lib-0.4.0-msvc.zip and unzip to C:\ta-lib.
This is a 32-bit binary release. If you want to use 64-bit Python, you will need to build a 64-bit version of the library. Some unofficial (and unsupported) instructions for building on 64-bit Windows 10, here for reference:
ta-lib-0.4.0-msvc.zipta-lib to C:\[Visual C++] Feature[VS2015 x64 Native Tools Command Prompt]C:\ta-lib\c\make\cdr\win32\msvcnmakeYou might also try these unofficial windows binaries for both 32-bit and 64-bit:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#ta-lib
下载了一个 TA_Lib‑0.4.24‑cp38‑cp38‑win_amd64.whl 包
$pip install wheel
安装whl包 $pip install TA_Lib‑0.4.24‑cp38‑cp38‑win_amd64.whl
与掘金量化数据库进行通信必须使用对应的账户与密码
取得日均线 talib.MA()

EXPMA指标,是一种趋向类指标,是以指数式递减加权的移动平均。
对应函数:talib.EMA()

MACD称为指数平滑移动平均线,是金融分析指标中常用的一个数据指标,用于对股票趋势的分析
对应函数:macd, signal, hist = talib.MACD(close)
macd, signal, hist = talib.MACD(close, fastperiod=x, slowperiod=y
signalperiod=z)
画出图来,长得和股票软件里的还是挺象的,
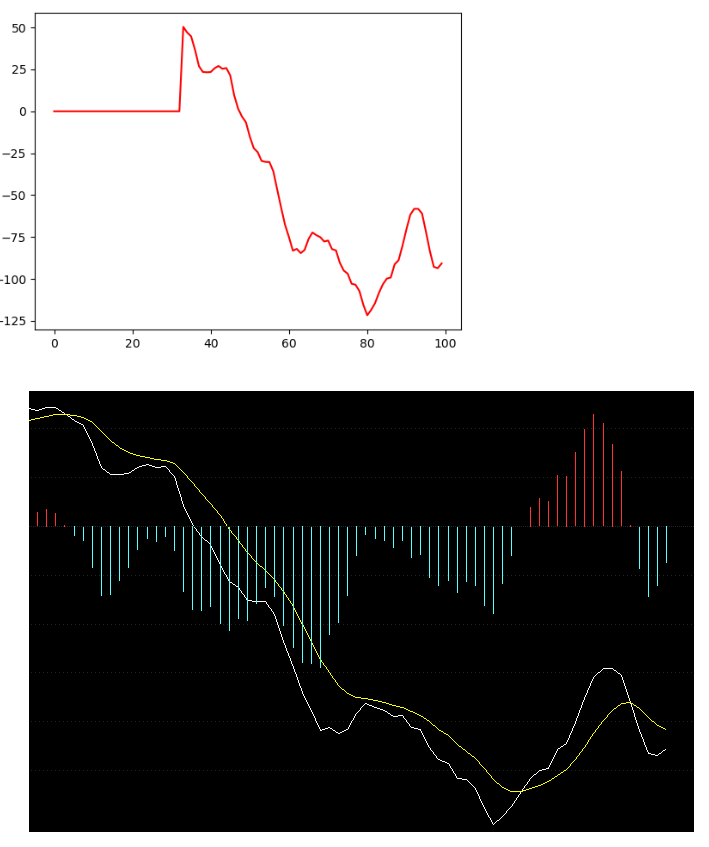
对于上涨的快慢,斜率表示一条直线(或曲线的切线)关于(横)坐标轴倾斜程度的量。它通常用直线(或曲线的切线)与(横)坐标轴夹角的正切,或两点的纵坐标之差与横坐标之差的比来表示。
使用diff函数计算MACD斜率数值的方法
macd_gradient = np.diff(macd)
init函数是回测程序的初始化程序,在这里进行数据的初始化,从本代码段中可以看到,这里通过context初始化了目标代码、时间周期以及所需要读取的字典。最后通过schedule函数对回测的执行规则做了设定,选择了回测算法以及时间规则。
def init(context):
#股票代码 宋城演艺
context.symbol = "SZSE.300144"
context.frequency = "1d"
context.fields = "open,high,low,close"
#每次购买股数
context.volume = 2000
schedule(schedule_func=algo, date_rule="1d", time_rule="09:35:00")
回测策略的关键是算法的设定。根据不同的金融产品对象设置不同的分析算法从而决定买卖点。
def algo(context):
now = context.now
last_day = get_previous_trading_date("SZSE", now)
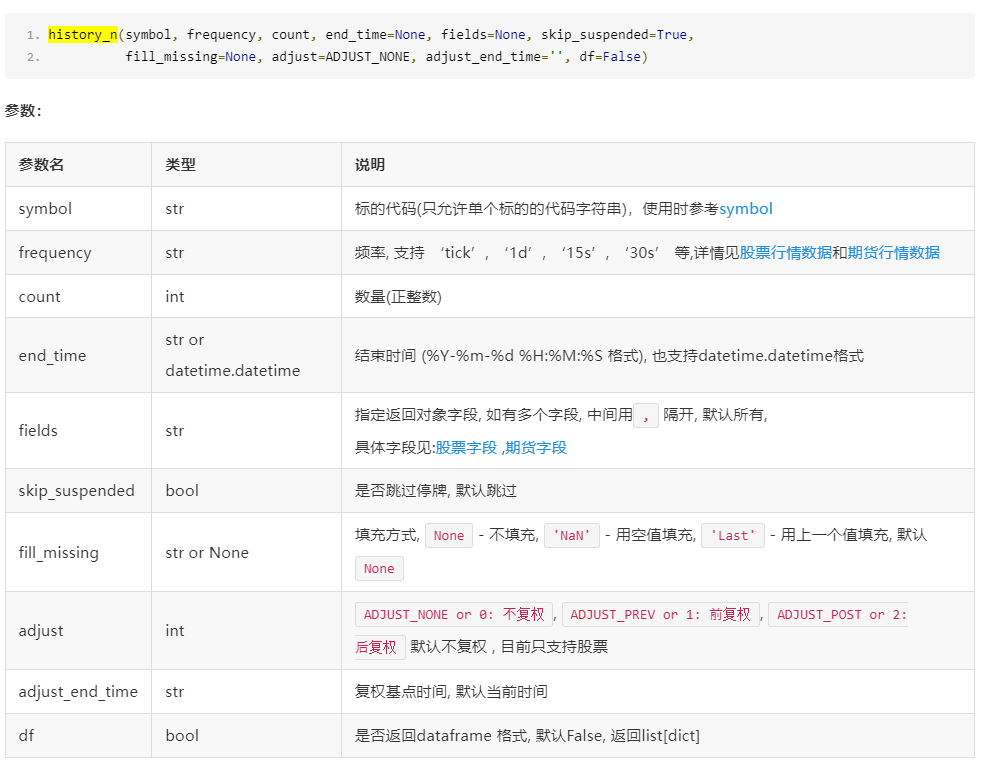
data = history_n(symbol=context.symbol, frequency=context.frequency, count=35,
end_time=now, fields=context.fields, fill_missing="last", adjust=ADJUST_PREV, df=True)
open = np.asarray((data["open"].values))
high = np.asarray((data["high"].values))
low = np.asarray((data["low"].values))
close = np.asarray((data["close"].values))
macd, _, _ = talib.MACD(close)
macd = macd[-1]
if macd > 0:
order_volume(symbol=context.symbol, volume=context.volume, side=PositionSide_Long,
order_type=OrderType_Market, position_effect=PositionEffect_Open)
print("买入")
elif macd < 0:
print("卖出")
order_volume(symbol=context.symbol, volume=context.volume, side=PositionSide_Short,
order_type=OrderType_Market, position_effect=PositionEffect_Close)
主方法中主要对账户信息、Python代码的名称、执行的类型、起止时间、复权方法进行设定。
if __name__ == '__main__':
'''
strategy_id策略ID, 由系统生成
filename文件名, 请与本文件名保持一致
mode运行模式, 实时模式:MODE_LIVE回测模式:MODE_BACKTEST
token绑定计算机的ID, 可在系统设置-密钥管理中生成
backtest_start_time回测开始时间
backtest_end_time回测结束时间
backtest_adjust股票复权方式, 不复权:ADJUST_NONE前复权:ADJUST_PREV后复权:ADJUST_POST
backtest_initial_cash回测初始资金
backtest_commission_ratio回测佣金比例
backtest_slippage_ratio回测滑点比例
'''
run(strategy_id='d570d331-a218-11ec-9ce7-c46xxxx0',
filename='main.py',
mode=MODE_BACKTEST,
token='1d2786e4ef9b90911axxxx1a2573e7',
backtest_start_time='2021-01-01 08:00:00',
backtest_end_time='2021-12-31 16:00:00',
backtest_adjust=ADJUST_PREV,
backtest_initial_cash=500000,
backtest_commission_ratio=0.0003,
backtest_slippage_ratio=0.0001)
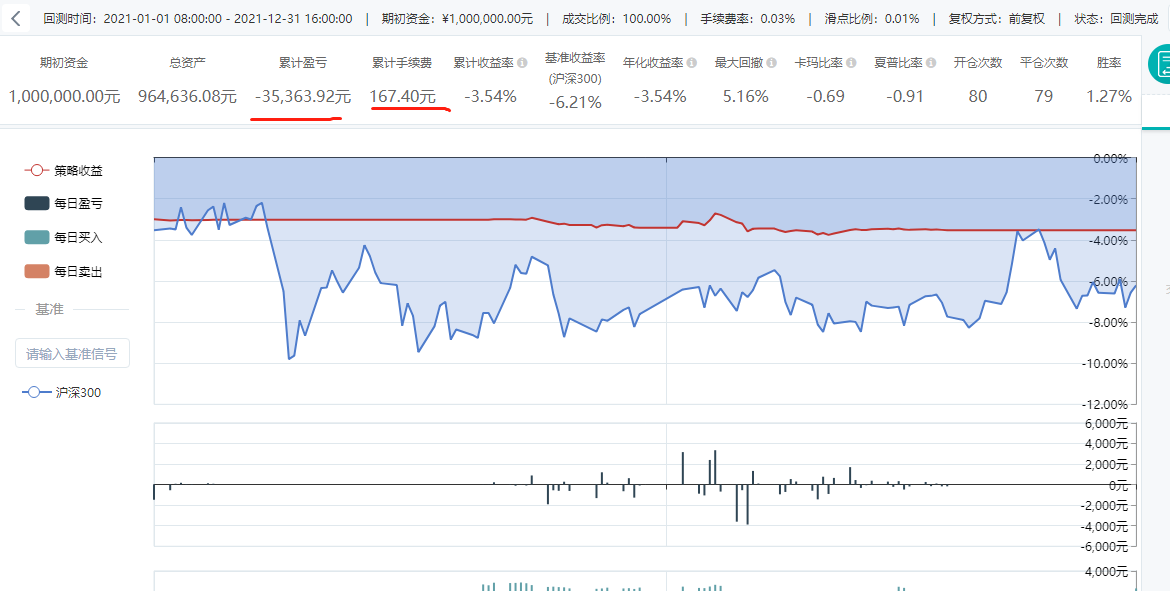
回测策略的核心是算法的使用
RSI(相对强弱指数)是通过比较一段时期内的平均收盘涨数和平均收盘跌数来分析市场买沽盘的意向和实力,从而做出未来市场的走势。一般真实使用时判定当RSI高于70时,股票可以被视为超买,是卖出的时候。当RSI低于30时,股票可以被视为超卖,是买入的时候。
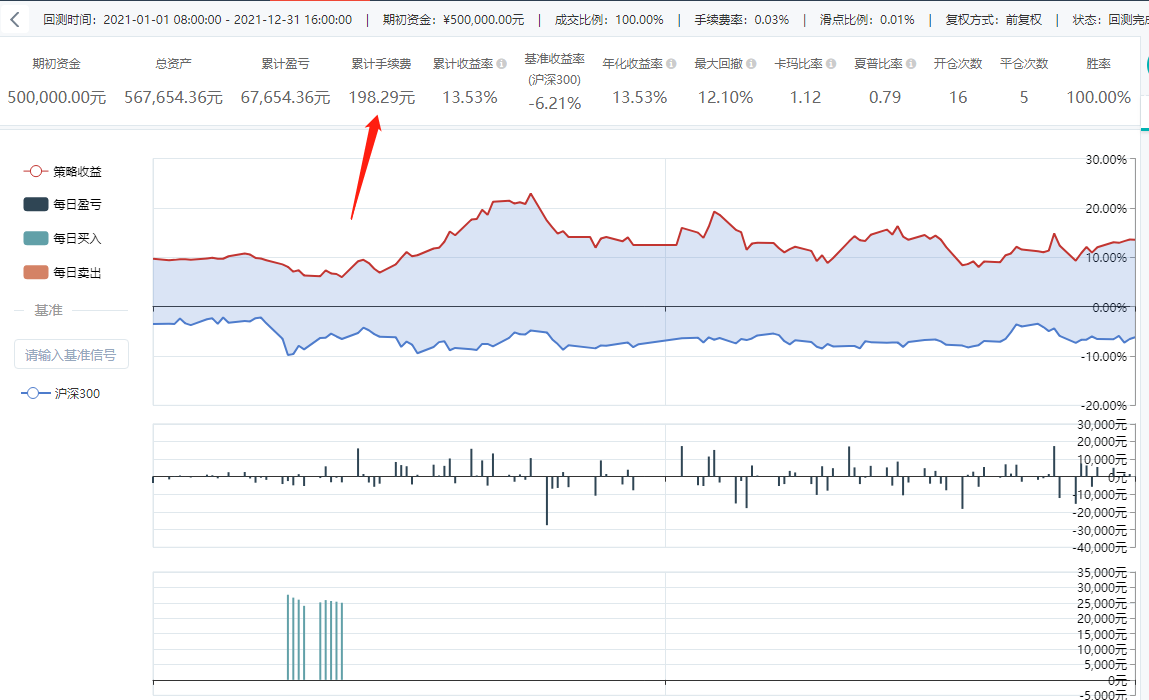
这个回测里的手续费好像少了一点。一年开仓次数16次,平仓5次,交易次数不算多,收益率13%,还是不错的。
布林线指标即BOLL指标,其英文全称是Bollinger Bands。布林线由约翰·布林先生创造,其利用统计原理求出股价的标准差以及信赖区间,从而确定股价的波动范围及未来走势,利用波带显示股价的安全高低价位,因而也被称为布林带。布林线还可以用于买卖点的设置,当股价高于这个波动区间时,即突破阻力线,说明股价虚高,执行卖出操作。而股价低于这个波动区间,即跌破支撑线,说明股价虚低,执行买入。
轨道线是趋势线概念的延伸,当股价沿道趋势上涨到某一价位水准时会遇到阻力,回档至某一水准时价格又获得支撑,轨道线就在接高点的延长线及接低点的延长线之间上下来回,当轨道线确立后,股价就可以非常容易地找出高低价位所在,投资人可依此判断来操作股票。
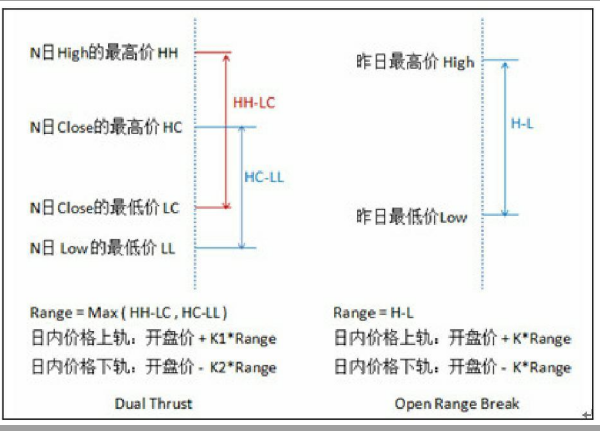
Dual Thrust策略
Dual Thrust简称DT,是Michael Chalek在80年代开发的,属于开盘区间突破类交易系统,以今日开盘价加/减一定比例的昨日振幅确定上下轨,。日内突破上轨时平空做多,突破下轨时平多做空。
国内A股的相关因子
1.规模因子:小市值因子
2.技术因子:动量反转因子。动量反转因子是典型的技术因子,指的是单个标的涨跌幅度的反转效应明显。
3.预测因子:预测收入的因子。预测因子指的是能够预测下一个财务周期的各种因子。
九类因子
规模因子,如总市值、流通市值、自由流通市值。
估值因子,如市盈率(TTM)、市净率、市销率、市现率、企业价值倍数。
成长因子,如营业收入同比增长率、营业利润同比增长率、归属于母公司的近利润同比增长率、经营活动产生的现金流金额同比增长率。
盈利因子,如净资产收益率(ROE)、总资产报酬率(ROA)、销售毛利率、销售净利率。
动量反转因子,如前一个月涨跌幅、前2个月涨跌幅、前3个月涨跌幅、前6个月涨跌幅。
交投因子,如前一个月日均换手率。
波动因子,如前一个月的波动率、前一个月的振幅。
股东因子,如户均持股比例、户均持股比例变化、机构持股比例变化。
一致性预测因子,如研报或者分析师预测当年净利润增长率、主营业务收入增长率、最近一个月预测净利润上调幅度、最近一个月预测主营业务收入上调幅度、最近一个月上调评级占比
选取因子的第一步就是从掘金量化所提供的财务数据表(掘金量化主界面→帮助中心→数据文档)中抽取特定的数据。函数:get_fundamentals_n()
建立股票池: get_history_constituents – 查询指数成份股的历史数据
在金融系统中产生能够表述某一方面问题的因子越来越多,大概可以分为估值与市值类因子、偿债能力和资本结构类因子、分析师预期类因子、均线型因子、成交量型因子、成长能力类因子、每股指标因子、现金流指标因子、盈利能力和收益质量类因子、能量型因子、营运能力类因子、超买超卖型因子、趋势型因子这些大类。
因子IC法来自于多因子模型的打分法,指的是选用若干能够对股票未来时间段收益产生预测作用的因子,根据每个因子在对应位置的状况给出股票在该位置上的得分,然后按照一定的权重将各个因子的得分相加,从而得到该股票各个因子的最终得分。
在打分模型中,各个因子的权重设定和计算非常重要

IC的计算公式实际上就是不同序列的相关系数的计算,那么IC值的计算用一句话解释就是:“IC值为因子与对应的下期收益率之间的关系”
corr = np.corrcoef()IC值的计算方法,即回归法。就是用该期的股票收益率对上期的因子值做回归,并用该期的因子值预测下期股票的收益率,取下期预测的收益率和下期实际收益率的相关系数。
在量化形式上,成长型投资主要是通过ROE、ROA、ROIC、营业收入增长率、主营业务利润率等参数来挖掘成长性相对更高的股票。
构建成长模型。将ROIC列为质量指标,另外构建包括EBITG(息税前收益增长率)、NPG(净利润增长率)、MPG(主营利润增长率)、GPG(毛利润增长率)、OPG(营业利润增长率)、OCG(经营现金流增长率)、NAG(净资产增长率)、EPSG(每股收益增长率)、ROEG(净资产收益率增长率)、GMPG(毛利率增长率)10个考核公司成长能力的指标。
要使用的因子:函数get_fundamentals_n()
霍华·罗斯曼认为只要在适当的价格买入稳定且持续成长获利的股票,不需要经常更换持股,投资报酬率必然指日可期。
霍华·罗斯曼强调其投资风格在于为投资大众建立均衡且以成长为导向的投资组合。其选股方式偏好大型股、管理良好且领导产业趋势以及产生实际报酬率的公司,不仅重视公司产生现金的能力,也强调有稳定成长能力的重要性。
(1)总市值大于等于50亿美元。(2)良好的财务结构。(3)较高的股东权益报酬。(4)拥有良好且持续的自由现金流量。(5)稳定持续的营收成长率。(6)优于比较指数的盈余报酬率。
用程序语言组织起来:(1)总市值≥市场平均值*1.0。(2)最近一季流动比率≥行业平均值。(3)近四季股东权益报酬率≥市场平均值。(4)最近三年CPS≥0且最近四季CPS≥0。(5)近四季营收成长率为6%至30%。(6)近四季盈余成长率为8%至50%。
技术面因子作为多因子策略的重要组成部分,已经越来越多地被量化基金和程序设计人员所使用。其主要作用是作为基本面选股的一个重要补充,解决了基本面选股策略中对买入时机的选择有所欠缺的问题。
基本面因子本质来源于公司的财务、供销、利润以及产出
技术面因子的组合计算更多涉及数学、统计等

一个回测成功率100%的中长线买卖例子
买点:
找到昨天之前成交量大于昨天的成交量(0.8倍),这个区间的天数大于30天。
昨天单日成交量大于该区间的平均成交量的2倍。
区间价格波动小于10%。
卖点:
5日均线值超过30日均线值的10%且换手率大于15。
5日均线值超过30日均线值的20%。
红利策略最初叫作“狗股策略”(Dogs of the Dow Theory),是由美国基金经理迈克尔·奥希金斯在1991年提出的。该策略的具体做法是每年年底在道琼斯工业平均指数成分股中找出10只股息率最高的股票,新年买入,一年后按股息率高低更新股票池,如此循环往复。
中证红利指数简称“中证红利”,指数代码为000922(上海)/399922(深圳)
关注。
股息率:股息率(Dividend Yield Ratio)是一年的总派息额与当时市价的比例。以占股票最后销售价格的百分数表示年度股息,该指标是投资收益率的简化形式。股息率是股息与股票价格之间的比率。在投资实践中,股息率是衡量企业是否具有投资价值的重要标尺之一。
市净率:市净率指的是每股股价与每股净资产的比率。市净率可用于股票投资分析,一般来说市净率较低的股票,投资价值较高,相反则投资价值较低。但在判断投资价值时,还要考虑当时的市场环境以及公司经营情况、盈利能力等因素。
市盈率:市盈率(Price Earnings ratio,即P/E ratio)也称“本益比”“股价收益比率”或“市价盈利比率”。
贝塔值:与大盘的联动波动率。
自相关波动率:自身的波动率。
构建一个基于指数的指数增强组合的步骤如下:
(1)根据自己的目标找到对应特征的指数。
(2)综合采用多个因子增强指数的特征。
多因子策略,就是根据各个因子的大小对股票进行打分,然后按照一定的权重加权得到一个总分,最后根据总分再对股票进行筛选。对于多因子模型的评价而言,实际上通过评分法回测出的股票组合收益率,就能够对备选的选股模型做出优劣评价
回归分析预测法是在分析市场现象自变量和因变量之间相关关系的基础上,建立变量之间的回归方程,并将回归方程作为预测模型,根据自变量在预测期的数量变化来预测因变量关系,大多表现为相关关系。
在处理测量数据时,经常要研究变量之间的关系。变量之间的关系一般分为两种,一种是完全确定关系,即函数关系;另一种是相关关系,即变量之间既存在着密切联系,但又不能由一个或多个变量的值求出另一个变量的值。
对于彼此联系比较紧密的变量,人们总希望建立一定的公式,以便变量之间互相推测。回归分析的任务就是用数学表达式来描述相关变量之间的关系。
回归分析的任务就是用数学表达式来描述相关变量之间的关系。
分为一元回归分析预测法和多元回归分析预测法。在一元回归分析预测法中,自变量只有一个,而在多元回归分析预测法中,自变量有两个以上。依据自变量和因变量之间的相关关系不同,可分为线性回归预测和非线性回归预测。
回归算法是一种基于已有数据的预测算法,其目的是研究数据特征因子与结果之间的因果关系。
y=a+βx+ε
一元线性回归模型。其中是常数。随机扰动项是无法直接观测的随机变量。
一般为了便于求解,将上述公式表示为:
y=a+bx
a是样本回归方程的常数项,也就是样本回归直线在Y轴上的截距,表示除自变量X以外的其他因素对因变量Y的平均影响量;b是样本回归系数,即样本回归直线的斜率,表示自变量X每增加一个单位,因变量Y的平均增加量。
每个回归模型都可以由一个回归函数表现出来,这样能够较好地表现出特征与结果之间的关系。
多元回归是指一个因变量(预报对象)、多个自变量(预报因子)的回归模型。基本方法是根据各变量的值算出交叉乘积和
由于各个自变量的单位可能不一样,因此自变量前系数的大小并不能说明该因素的重要程度
最小二乘法(LS算法)是一种数学优化技术,也是一种回归分析的常用解法。它通过最小化误差的平方和寻找数据的最佳函数匹配。
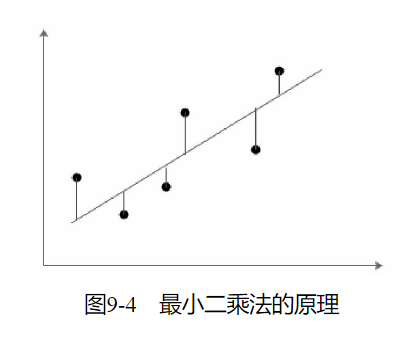
若干个点依次分布在向量空间中,如果希望找出一条直线和这些点达到最佳匹配,最简单的方法就是希望这些点到直线的值最小,即下面的最小二乘法实现公式最小
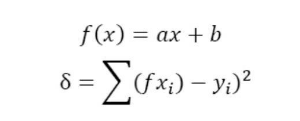
对于给定的数据(xi,yi)(i=1,…,m),在确定的假设空间H中,求解f(x)∈H,使得残差δ=∑(f(xi)-yi)2的L2-范数最小。
import statsmodels.api as sm x_ = sm.add_constant((x1)) model = sm.OLS(y, x_) results = model.fit()
随机梯度算法的原理 : 在下降一个梯度的阶层后,寻找一个当前获得的最大坡度继续下降。随机梯度下降算法就是不停地寻找某个节点中下降幅度最大的那个趋势进行迭代计算,直到将数据收缩到符合要求的范围为止。
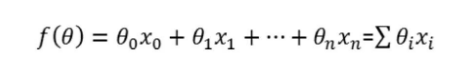
逻辑回归是一种广义的线性回归分析模型,常用于数据挖掘、疾病自动诊断、经济预测等领域。
逻辑回归的主要用途如下。
寻找危险因素:寻找某一疾病的危险因素;
预测:如果已经拟合出回归模型,那么可以根据模型预测在不同自变量的情况下发生某病或某种情况的概率有多大。
判别:根据逻辑回归模型判断某人属于某病或属于某种情况的概率有多大。
支持向量机实际上是一种有监督的机器学习算法,支持向量机解决的是有监督的二元分类问题(supervised binary classification)。
SVM的作用对象是样本的特征空间(feature space),它是一个有限维度的向量空间,每个维度对应着样本的一个特征,而这些特征组合起来可以很好地描述被分类的样本。
SVM算法会根据历史数据在特征空间内构建一个超平面(hyperplane),它将特征空间线性分割为两部分,对应着分类问题的两类,分别位于超平面的两侧。构建超平面的过程就是模型训练过程。对于一个给定的新样本,根据它的特征值,它会被放在超平面两侧中的某一侧,这便完成了分类。SVM是一个非概率的线性分类器。这是因为SVM模型回答的是非此即彼的问题,新样本会被确定地分到两类中的某一类。
SVM的强大之处在于,它不仅仅局限于是一个高维空间的线性分类器。它通过非线性的核函数(kernel functions)把原始的特征空间映射到更高维的特征空间(可以是无限维的),在高维空间中再将这些样本点线性分割。
资本资产定价模型(Capital Asset Pricing Model,CAPM)是由美国学者夏普(William Sharpe)、林特纳(John Lintner)、特里诺(Jack Treynor)和莫辛(Jan Mossin)等人于1964年在资产组合理论和资本市场理论的基础上发展起来的。
CAPM资产定价模型假设所有投资者都按马科维茨的资产选择理论进行投资,对期望收益、方差和协方差等的估计完全相同,投资人可以自由借贷。基于这样的假设,CAPM资产定价模型研究的重点在于探求风险资产收益与风险的数量关系,即为了补偿某一特定程度的风险,投资者应该获得多少的报酬率。
CAPM的定价模型
定价模型如下:
Ra=rf+βa×(rm-rf)
rf(Risk Free Rate)是无风险回报率(相对于一年期国债)。
βa是证券的Beta系数。Beta系数是用以度量一项资产系统风险的指针,是用来衡量一种证券或一个投资组合相对总体市场的波动性(volatility)的一种风险评估工具。
rm是市场期望的回报率(Expected Market Return)。
rm-rf是股票市场溢价(Equity Market Premium,EMP)。
CAPM定价模型需要大量的假设,归类如下:
投资者希望财富越多越好,效用是财富的函数,财富又是投资收益率的函数,因此可以认为效用为收益率的函数。
投资者能事先知道投资收益率的概率分布为正态分布。
投资风险用投资收益率的方差或标准差标识。
影响投资决策的主要因素为期望收益率和风险两项。
投资者都遵守主宰原则(Dominance Rule),即同一风险水平下,选择收益率较高的证券;同一收益率水平下,选择风险较低的证券。
可以在无风险折现率R的水平下无限制地借入或贷出资金。
所有投资者对证券收益率概率分布的看法一致,因此市场上的效率边界只有一条。
所有投资者具有相同的投资期限,而且只有一期。
所有的证券投资可以无限制地细分,在任何一个投资组合里可以含有非整数股份。
买卖证券时没有税负及交易成本。
所有投资者可以及时免费获得充分的市场信息。
不存在通货膨胀,且折现率不变。
投资者具有相同预期,即他们对预期收益率、标准差和证券之间的协方差具有相同的预期值。
第一,投资者是理性的,而且严格按照马科维茨模型的规则进行多样化的投资,并将从有效边界的某处选择投资组合;第二,资本市场是完美/完全市场,没有任何摩擦阻碍投资。
Fama-French三因子模型
Fama和French分别分析了原因,他们认为:
市值比较小的公司通常规模比较小,公司相对而言没那么稳定,因此风险较大,需要获得更高的收益来补偿。
此外就是账面市值比。账面市值比就是账面的所有者权益除以市值(以下简称B/M)。若B/M较高,则说明市场上对公司的估值比公司自己的估值更低。这些公司一般都是销售状况或者盈利能力不是十分好的公司,因此相对于低B/M的公司来说需要更高的收益来补偿。
一般对于股票收益的解释认为收益风险同源。市场风险是唯一能给股票带来超额收益的风险。但是基于以上两个事实的研究发现,除了市场风险外,Fama-French认为市场上还存在市值风险、账面市值比风险等,据此建立的模型被称为“Fama-French三因子模型”。
对于传统的股票模型来说,股票市场的Beta值不能解释不同股票回报率的差异。在此基础上,有实证研究表明,股票市值、账面市值比、财务杠杆(leverage)和市盈率的倒数(E/P)等指标可以很好地解释股票收益
Ri=ai+biRm+siE(SMB)+liE(HMI)+εi
Ri指的是股票相对无风险投资(一年期国债)的期望额外收益率。Ri=E(ri-rf)
Rm,为市场相对无风险投资的期望超额收益率
E(SMB)是小市值公司相对大市值公司股票的期望超额收益率,
E(HMI)则是高B/M公司股票比起低B/M公司股票的期望超额收益率,
εi 是回归残差项。
Fama-French在1993年提出三因子模型之后,Carhart在1997年提出了动量因子(Momentum)从而得到四因子模型,Fama-French 2015年在三因子的基础上继续增加了两个因子:盈利能力因子RMW和投资因子CMA,得到五因子模型。
选股的核心思想在于寻找价格低于内在价值的股票,从而获取未来价格修复的收益
PB-ROE模型介绍(Price/Book ratio-Return On Equity)
PB=股价/账面价值
ROE=[(净利润-优先股股利)/期初普通股股东权益]*100%
可以简单地理解PB-ROE就是“市净率-净资产收益率”
相关性
对于pandas来说,相关系数并不是由pandas根函数提供的,而是由DataFrame对象内置的计算器计算出的。concat是连接函数,将不同的数据进行连接,axis是内置参数,用以决定从哪里进行连接,这里由于需要计算不同的数组之间的相关系数,因此选择将数据连接成不同的行,计算不同行之间的相关系数。
arr = pd.concat([arr_a,arr_b],axis=1)
相关系数:corr = arr.corr()
均值:np.mean()
方差:np.var()
标准差: np.std()
arr = pd.concat([arr_a,arr_b],axis=1)
协方差 :cov = arr.cov()
协方差是关于如何调节协变量对因变量的影响效应,从而更加有效地分析实验处理效应的一种统计技术,也是对实验进行统计控制的一种综合方差分析和回归分析的方法。协方差只表示线性相关的方向,取值正无穷到负无穷。也就是说,协方差为正值,说明一个变量变大,另一个变量也变大;取负值说明一个变量变大,另一个变量变小;取0说明两个变量没有相关关系。需要注意的是,协方差的绝对值不反映线性相关的程度。
相关系数不仅表示线性相关的方向,还表示线性相关的程度,取值[-1,1]。也就是说,相关系数为正值,说明一个变量变大,另一个变量也变大;取负值说明一个变量变大,另一个变量变小;取0说明两个变量没有相关关系。同时,相关系数的绝对值越接近1,线性关系越显著。通常情况下,取绝对值后,0~0.09为没有相关性,0.1~0.3为弱相关,0.3~0.5为中等相关,0.5~1.0为强相关。
配对交易是一种基于统计建模分析的交易策略,它是通过计算不同股票之间是否具有同样的趋势与走势进行股票交易的策略。
平稳性就是在一个时间序列中不随外界噪音改变而能够保持稳定不变的性质
相关系数是对两组数据集直接的相关性进行计算,而协整性是在不同的数据之间计算其差值并对其差值进行分析
两只股票的价差较为平稳,其在变化过程中,前进的方向也是一致的。这种性质被称为“协整性”。
协整性的第一步是对序列进行平稳性检验。
一般来说,平稳性分为严平稳性和弱平稳性。严平稳性是指一个序列的分布函数始终不变,而弱平稳性是指序列具有不变的统计常量。一般说的平稳性是弱平稳性。在时间序列分析中,常用“单位根检验”来判断一个过程是否为弱平稳性。
单位根检验:st = sm.tsa.stattools.adfuller(arr_a)
第一个参数为“Test Statistic”,第四个参数为测试的关键参数点。若第一个参数小于第四个参数中的“1%”所对应的值,则可认为序列没有单位根,为平稳序列;若第一个参数大于第四个参数中的“10%”所对应的值,则可认为序列存在单位根,为非平稳序列
对于非平稳序列转化为平稳序列,最简单的办法就是“差分法”。非平稳序列往往一次到两次差分之后,就会变成平稳序列。
经过一次差分计算的序列称为“一阶差分”,以此类推,经过n次差分计算的序列称为“n阶序列”。
“差分法”就是序列后一点的值减去当前点的值,用公式表示为yt-y(t-1)。值得注意的是,每一次差分之后,都会少一个序列值。
计算差分的函数:arr_b = np.diff(arr_a)
配对交易的算法
(1)找出具有较强相关性的股票,建立配对股票模式。这样一般要求其相对系数大于0.95。
(2)分别检验配对标的的平稳性,一般来说,股票都不会直接是平稳性序列,因此在其基础上检验配对的股票是否具有同阶差分协整性。
(3)做系数回归分析,确立系数和截距值。
(4)用单位根检验新生成的值残差是否平稳,若平稳,则两个时序是协整的,否则结束,实验失败。
(5)根据策略编写代码。
此时此刻,在经历了连续一个月每天10点准时开抢深圳隔离酒店、每周二全天刷港珠澳大桥车票的屡败屡战和万分崩溃之后,笔者坐上了香港飞成都的CX986航班,开始隔离,曲线回深。
自1月27日回港至今,笔者几乎完整经历了香港的第五波Omicron疫情,从每天几十,到几百,到几千,到几万,再到如今的“事实躺平”。与此同时,内地也正面临Omicron的高度挑战,今日上海新增感染人数已超过 1600 人,全国连续多日日增 5000 人左右。
香港在欧美“躺平”和内地“坚挺”之间的“仰卧起坐”,成为了支持内地防疫政策的良好数据参考。
本文用数据说话,准备分两期回答如下问题:
上期:
1,截止目前,香港到底感染了多少人?
2,Omicron的典型发病过程是怎样的?
3,香港Omicron死亡率真高吗?
4,Omicron的后遗症可怕吗?
下期:
5,如何开展居家抗疫,准备哪些必要物资?
6,香港为什么一再推迟全民核酸检测,做与不做临界点在哪里?
7,为什么香港只能做仰卧起坐?
8,内地本轮疫情,香港是罪魁祸首吗?香港决定继续放开,内地后续怎么办?
9,香港的第五波疫情,对内地防控调整有哪些参考意义?
香港卫生署卫生医护中心和医院管理局发布的官方数据显示:截止3月24日,第五波疫情总确诊人数逾 1,088,593 宗,其中经过核酸检测确诊 698,253 宗,经过抗原快速检测上报 390,340 宗。香港总人口为 7,394,700 人,则感染人口比例为 14.72%。
")
截止3月24日,香港第五波Omicron疫情确诊人数与人口数(按年龄组别)
值得注意的是,Omicron对各年龄段无差别打击。在各个年龄段中,感染率(该年龄段感染人数÷该年龄段的人口数)在 8%-16%之间,差别非常细微,这与早期“新冠病毒主要攻击老年人”的特点非常不同。20岁到60岁的中年人,感染率甚至比小孩和老人还略高一些,这跟他们的社交范围有关。
")
截止3月24日,香港第五波Omicron疫情感染率(按年龄组别)
尽管此数据看起来已经很大,但仍然只是冰山一角。至今,香港并没有进行过哪怕一轮全民核酸检测,官方并不能掌握真实情况,未纳入统计的情况包括:
1、收到强制检测令的人士,不配合强检或忘记去强检。
笔者所在的小区在春节后因排污管测出环境阳性,随即列入围封强检。尽管围封强检仅一晚,第二天一早就可放开,仍然有不少家庭敲门无人应答,到底是真无人在家还是不想配合无法鉴定。同时,香港对个人隐私保护严格,也未公布无人应答的家庭信息,最后在当晚检测出3名阳性患者后,第二天一早就完全解封。再如,香港版的场所码——安心出行,在疫情初期,也曾对与确诊患者有地点交集的人士发出强制检测,但强检通知仅仅是一条短信而已,不少人没有看到,也有人看到了又忘记去检测,最后也不了了之。强检而不检,在内地是难以想象的,但在香港何以如此“随意”,这就涉及到所谓政府的强制权力问题了,后面再单独分析。
2、自行快速抗原检测为阳性,但不上报政府。
内地刚刚放开的快速抗原检测,在香港已经上市了很长时间。第五波疫情以来,相信几乎每个家庭都备有快速检测盒,政府也在免费发放快速检测盒。按照政府的要求,自行检测阳性的人士,应当通过专门的网站上报。但截止目前,以“全民自检”代替“全民强检”的上报案例仅为39万宗,远低于核酸检测的近70万宗,显然数据偏差很大。
为什么自检阳性的人,不愿上报政府呢?这个问题对正在推行自行抗原检测的内地,有非常重要的参考价值。
首先,Omicron的绝大多数都是无症状感染者(今天3月25日上海发布:确诊病例 29 例,无症状感染者 1580 例)和轻症患者,前者无需治疗、后者按照感冒对症吃药(如必理通、扑热息痛、莲花清瘟等,去医院也是这些药)即可痊愈转阴。只要家庭有独立的房间安排患者隔离,就没有上报的动力,因为上报并不能给患者和家庭带来额外的好处,反而带来更多的限制,包括:可能被送去条件更差的方舱,对家庭其他成员(大陆定义为密接者)的禁足令等等。其次,自检阳性患者,如果不上报,政府实际上是不可能追溯到该行为的,因为自检人士完全可自称未进行过自我检测,故不知道自己是阳性。再次,即使上报,由于前期确诊的人数太多,政府事实上也没有更多的资源来快速跟进处理这一大批无症状和轻症患者,只是在上报后自动回复一个短信表达“收到”,然后会在数天内给家庭地址寄来一个医疗包,但不少人表示,等收到医疗包时,病症都好得差不多了。综上,自检阳性上报政府,一无法律强制(也无法强制),二无额外收益,只是凭空增加限制,那就全凭自觉了。同理,内地开放抗原快速自检后,如何确保阳性主动上报,也是个问题。
3、没有检测的无症状感染者和轻症者。
前面说了,至今为止,香港未做全民强制核酸检测,无症状感染者也不会在完全没感觉的时候,自行做快速抗原检测。对于轻症患者,只要家里没有老人小孩需要保护,很多年轻人不过嗓子疼而已,连发烧也没有,也可能不做检测。
既然政府数据是失真的,那么有没有更可信的数据呢?3月22日,香港大学医学院给出了最新的数学模型计算结果,截止3月20日,已感染人数高达 440 万人,占香港总人数的 60%。
")
来源:港大医学院3月22日数学模型
这个数据是否可信呢?由于这个发布会才几天,政府还没有对此做出评价。但在上一次(3月15日)港大医学院做出已感染人数358万的估算时,卫生防护中心传染病处认为该估算合理,并表示:每1个已发现的感染者背后,可能有3至4个未发现的感染者。
从笔者在香港的朋友圈来开,如果以家庭为单位,一半左右的朋友都中招了。再考虑到笔者的朋友圈,一来是内地人为主,都怕新冠;二来家里都有小孩,担心加剧;三来在港没有七大姑八大姨,社交关系简单,应该算疫情下线。因此,60%是一个靠谱的中招比例。
视频来源:香港01
60%的感染人数,无论是病程发展过程、死亡情况、后遗症等问题,都具备了数据分析的基础,接下来分三个问题来一一讨论。
给武汉制造了第一波疫情的新冠病毒“野生株”,给大家带来了太过震撼的记忆。但新冠进入到第三年,经过了多轮变异,它也在学会跟人类共存。病毒的目的不是杀死宿主,毕竟宿主死了,它也死了。按照自然进化规律,为了让病毒世世代代繁衍,它的最优策略是降低毒性,提高传播性。因此,进化到了现在的Omicron变异株。
下图为香港疫情期间广为流传的发病过程示意图。笔者身边中招的朋友不在少数,无一例外地按此走完了从感染到转阴的全过程,中间的差异就是提前或延后一两天日而已。
")
非常靠谱的Omicron病程发展图
Days 是时间轴,表示天数,其中D0为感染日。
Infectiousness 曲线表示传染性,曲线越高,传染性越强。
Symptoms 色带表示症状,颜色越深,症状越明显。
D1-D3:潜伏期。患者逐渐开始有感觉,一般表现就是嗓子不舒服。但此时快速检测仍然为阴性,患者分不清到底是正常的嗓子不舒服还是中招。幸运的是,此时的传染性也非常低,否则Omicron的传染性还要突飞猛进。
D4-D6:发病期。病程进入快速发展期。如果自身免疫系统在此时打败了Omicron,恭喜你,成为了无症状感染者;如果免疫系统没有抗住这一波攻击,则患者开始发烧、咳嗽、嗓子疼、肌肉酸痛等症状,轻症患者基本在D6不适感达到顶峰;重症患者此时会非常不适,需要送院救治,不在本讨论范围。随着病程加深,抗原浓度也开始明显,快速抗原检测从D4的浅色T线,逐渐变成D6的深色T线。
D7-D10:康复期。疫苗训练过几轮的免疫系统,逐渐打败Omicron,从D7开始,症状逐渐消失,有时甚至忘记吃药。病患的生理不适,慢慢被隔离的心理不适所取代,恨不得每个小时测一次,看是否转阴。D9-D10,基本可以转阴。连续两日转阴后,传染性基本也消失,按照香港规矩,即可解除隔离回归正常生活。有不少案例,在D8或D9时,T线的颜色还是比较深,但可能一夜之后突然就消失了,没有颜色逐渐变浅的过程,所以患者并不要因为颜色没有变浅而着急。
综上所述,Omicron的不适集中在D3-D7,共计5天,传染性集中在D4-D9,共计6天,抗原阳性检测集中在D4-D10,共计7天。大家可以自行跟感冒进行对比,结论不言而喻。
首先声明,笔者并非医学专业出生,以下讨论只是基于常识(Common Sense)展开,不对之处,敬请各位读者自行判断。
截止3月24日,香港第五波Omicron疫情,总计死亡人数 6557 人,死亡率(死亡人数/人口总数)为 0.08%,即每万人死亡 8 人,病死率(死亡人数/感染人数)为 0.6%,万感染者死亡 60人。无怪乎,张文宏医生3月14日在华山感染官微上转文表示:在实现广泛接种和自然感染率的国家,新冠病毒的病死率已经低于流感。
")
来源:香港卫生署《2019冠狀病毒病第5波數據》
但是如果我们细究80岁以上老人的情况,可以明显看到,其死亡率为 1.2%,即每100个80岁以上老人死亡了1.2人,病死率高达 9.3%,即每10个感染的80岁以上老人差不多就要死亡1人。应该说,这就是本轮疫情媒体最关注的点,也是最为诟病香港病死率高的点。
关于此点,有几个重要概念必须要说明,否则笼统地说病死率高意义不大。
首先,张文宏医生在说新冠病死率低于流感时,有一个重要前提,即实现广泛接种和自然感染率。但很不幸,香港前四波疫情控制得非常优秀(极低的自由限制,快速的动态清零),反而一方面让自然感染率低,另一方面让老人认为接种疫苗的风险可能大于其收益。当时,香港主要是mRNA疫苗复必泰和灭活疫苗科兴生物。对于前者,社会普遍认为存在未知风险,不利于老人和小孩接种,对于后者,则很大程度上延续了对内地的一贯偏见,认为科兴生物没有太大作用。最后的结果就是两者都没打。所以张文宏医生的前提不复存在,不管是哪个年龄段,死亡病例都有 60%-70% 没有打疫苗,20% 左右仅打了一针疫苗,没有完成全程接种,两种情况合计,就占到死亡病例的 80%-90% 左右。
所以,重点是,打针!打针!打针!
")
来源:香港01
其次,80岁以上的死亡病例,占到了香港所有死亡病例的 70%,可以叫做绝大多数。很遗憾,笔者没有拿到80岁以上病例的具体年龄,只知道最低年龄是80岁,平均年龄是多少并不清楚,只能姑且保守认为在 85 岁左右。有意思的是,联合国人居署发布的2021年预期寿命排行榜,香港冠绝全球,为 85.29 岁。因此,可以得出一个显而易见的结论,占香港绝大多数死亡病例的保守平均死亡年龄,跟香港本身的预期寿命非常接近。这背后引申出来的意义,难以言说但显而易见。
再次,新冠死亡的统计,其实包含了三类人。第一类叫做死于新冠(die of),即直接在临床上死于新冠病毒;第二类叫死时带毒(die with),即死亡原因与新冠病毒无关,但同时验出身体带有新冠病毒,例如有坠楼、中风等人士,入院后发现阳性,但无新冠病症。当然,这两类有时难以判断,所以第三类为原因暂时不明的。
香港政府专家顾问、中文大学呼吸系统科讲座教授许树昌分析了120例第五波死亡个案,结论非常有意思,死于新冠和死时带毒的比例分别是38%和37%,几乎持平。这也是当前新冠统计上的一大有意思的结论。
视频来源:香港01
综上所述,Omicron已经是温和的病毒,大家不用再以新冠初期武汉病情来看待当前的疫情,否则就是刻舟求剑。病毒都在进化,何况人呢?
人类畏惧病毒,无外乎两个方面,一是得病过程的痛苦甚至死亡,一是病愈之后可能导致的长期后遗症。
关于第一个方面,前文已经说了,绝大多数人都是无症状和轻症,得病过程既不痛苦也没那么容易死亡。那值得我们继续把他当成一个极端Case的理由,就只剩下后遗症了。
Omicron病毒,是2021年下半年才开始流行,香港是2022年春节才开始大爆发。因此,一个简单的逻辑,目前大多数所谓对新冠病毒的后遗症研究,要么并不是针对Omicron变异株的,要么就是才刚刚开始。
对于前者,一个典型案例是:近期,牛津大学在《Nature》杂志上发表的论文《SARS-CoV-2 is associated with changes in brain structure in UK Biobank》。这是一个怂人听闻的题目,新冠和人类脑部结构的改变有关!一时间,各种解读的公众号喧嚣尘上,并以此来解释为什么新冠后会丧失味觉和嗅觉,就是因为这两个区域的脑神经受损了。但仔细看看文章就可以发现,该文采集新冠病人脑成像数据的时点为2021年4月,当时,英国流行的是Delta变异株,则这部分病人应该感染的是此前的Alpha、Beta、Gamma变异株,Omicron几乎可以肯定不在此列。
对于后者,至少在香港都才刚刚转阴不久,还没有明确的数据。后遗症不会凭空产生,一定跟发病时对身体的损伤有关。大量的无症状感染者,说明自身免疫力已经将Omicron扼杀在萌芽阶段,更很难想象还能具有延迟杀伤力。轻症患者的临床表现来看,Omicron主要攻击上呼吸道,并没有攻击到肺部,因此,在香港Omicron被戏称为“新冠上呼吸道感染”,而非“新冠肺炎”,既然肺部并没有受损,也很难想象后续反而受损的可能。至于还有些康复患者接受媒体采访时表明,自己体能下降、注意力不集中、焦虑、记忆力差、睡眠习惯改变等,我只想说,过个春节大吃大喝,再加上居家隔离10多天,就是个好人也会有这些“后遗症”。如果去研究一下小朋友天天对着电脑上网课的后遗症,恐怕比此更甚;再研究一下笔者这类两地家庭,真心后遗症到想死!再次强调,笔者不是医学专业出生,以下皆为个人理解。我想强调的是,Omicron的后遗症还缺乏研究,目前的夸大,并不是真正的科学结论。
作者简介:阎镜予,香港中文大学博士,星河产业集团常务副总裁,星河资本合伙人。曾任职于香港中文大学、深圳市发改委,负责深圳市23个战略性新兴产业基地集聚区的规划建设工作,参与制定深圳市总部经济政策,目前负责星河WORLD园区的管理运营,并投资了云从科技、太和水、美味不用等、星际荣耀、国星宇航等企业。
转自:https://mp.weixin.qq.com/s/Ucwkb6PLD-1OmQsl4P3YzQ