chp1 走进量化交易
基于市场非有效或弱有效的理论基础之上
定量投资正是在找估值洼地,通过全面、系统性的扫描捕捉错误定价、错误估值带来的机会。
统计套利是利用证券价格的历史统计规律进行套利,是一种风险套利
一类是利用股票的收益率序列建模,目标是在组合的Beta值等于零的前提下实现Alpha收益,我们称之为Beta中性策略。
另一类是利用股票价格序列的协整关系建模,我们称之为协整策略。
算法交易分为被动型算法交易、主动型算法交易、综合型算法交易三大类
chp3 Python类库的使用——数据处理及可视化展示
建议读者使用已有的类库解决问题而不是自行编写相应的代码
数据处理的最终目的就是使用不同的特征属性对目标进行区分和计算。已有的目标是观察和记录的结果,而数据处理的过程就是创建一个可进行目标识别的模型的过程。
建立模型的过程称为数据处理的训练过程,其速度和正确率主要取决于算法的选择,而算法是目标和属性之间建立某种一一对应关系的过程。
当数据处理建模的最终目标是求得一个具体数值时,即目标是一个数字,那么数据处理建模的过程基本上可以被转化为回归问题,差别在于是逻辑回归还是线性回归。
对于目标为布尔型变量时,问题大多数被称为分类问题,而常用的建模方法是决策树方法。一般来说,当分类的目标是两个的时候,问题被转化为二元分类;而分类的结果多于两个的时候,分类称为多元分类。
数据处理的数据往往来自于现实社会,因此可能数据集中大多数的数据都会有某些特征属性缺失,而解决的办法往往是采用均值或者与目标数据近似的数据特征属性替代。
NumPy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效得多
计算数据集的和、均值、标准差以及方差
print(np.sum(col1))
print(np.mean(col1))
print(np.std(col1))
print(np.var(col1))
图形化数据处理——Matplotlib包的使用
$pip install pylab
$pip install scipy
$pip install matplotlib
画图
import numpy as np
import scipy.stats as stats
import matplotlib.pylab as pylab
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False],
[4,116,70.8,1,False],[5,270,150,4,True]])
col1 = []
for row in data:
print(row)
col1.append(row[0, 1])
stats.probplot(col1, plot=pylab)
pylab.show()
scipy是专门进行数据处理的数据处理包,probplot计算了col1数据集中数据在正态分布下的偏离程度。
不同的属性对于数据处理来说,需要一个统一的度量进行计算,即需要对其相似度进行计算。常用的两种,即欧几里得相似度计算和余弦相似度计算
欧几里得距离(Euclidean Distance)是最常用的计算距离的公式,它用来表示三维空间中两个点的真实距离。欧几里得相似度计算是一种基于用户之间直线距离的计算方式。在相似度计算中,不同的物品或者用户可以将其定义为不同的坐标点,而将特定目标定位为坐标原点。使用欧几里得距离计算两个点之间的绝对距离。
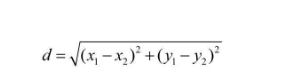
欧几里得的计算数值与最终的相似度计算成反比,欧氏距离越小,两组数据相似度就越大,欧氏距离越大,两组数据相似度就越小。因此,在实际中往往使用欧几里得距离的倒数作为相似度计算的近似值,即使用1/(d+1)作为近似值。
与欧几里得距离相类似,余弦相似度也将特定目标(物品或者用户)作为坐标上的点,但不是坐标原点,与特定的计算目标进行夹角计算
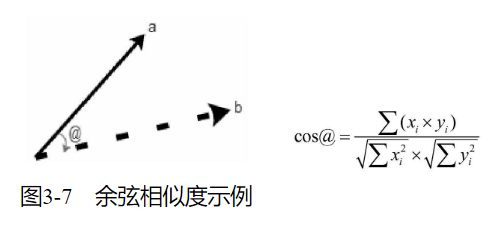
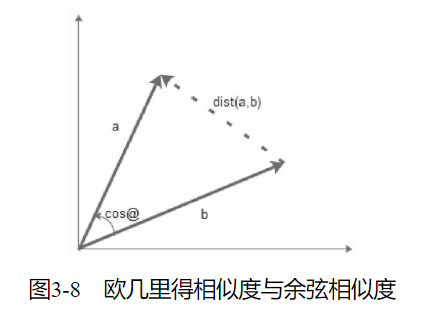
欧几里得相似度以目标绝对距离作为衡量的标准,而余弦相似度以目标差异的大小作为衡量标准。欧几里得相似度注重目标之间的差异,与目标在空间中的位置直接相关。而余弦相似度是不同目标在空间中的夹角,更加表现在前进趋势上的差异。
欧几里得相似度用以表现不同目标的绝对差异性,从而分析目标之间的相似度与差异情况。而余弦相似度更多的是对目标从方向趋势上区分,对特定坐标数字不敏感。
在分析用户相似度时,更多的是使用欧几里得相似度而不是余弦相似度对其进行计算。余弦相似度更好地区分了用户的分离状态。
四分位图是一个以更好、更直观的方式来识别数据中异常值的方法,比起数据处理的其他方式,它能够更有效地让分析人员判断离群值。
数据的标准化是将数据根据自身一定比例进行处理,使之落入一个小的特定区间,一般为(-1,1)之间。目的是去除数据的单位限制,将其转化为无量纲的纯数值,使得不同单位或量级的指标能够进行比较和加权,其中最常用的就是0-1标准化(0-1 normalization)和Z-score标准化(zero-mean normalization)。
0-1标准化也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间
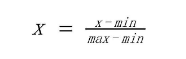
Z-score标准化也叫标准差标准化,经过处理的数据符合标准正态分布,即均值为0,标准差为1
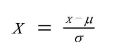
μ为所有样本数据的均值,σ为所有样本数据的标准差。
对于每种单独的数据属性来说,可以通过数据的四分位法进行处理、查找和寻找离群值,从而对其进行分析处理。但是对于属性之间的横向比较,每个目标行属性之间的比较,使用四分位法则较难判断
平行坐标(Parallel Coordinates)是一种常用的可视化方法,用于对高维几何和多元数据进行可视化。
热点图是一种判断属性相关性的常用方法,根据不同目标行数据对应的数据相关性进行检测。
chp4 掘金量化
使用掘金量化相比较其他平台的好处在于,可以使用Python IDE编辑器进行数据处理和编辑,并通过掘金终端获取回测结果。
手动下载SDK
$ python.exe -m pip install gm -i https://pypi.doubanio.com/simple
点击我的策略可查看回测记录

点击可查看详情
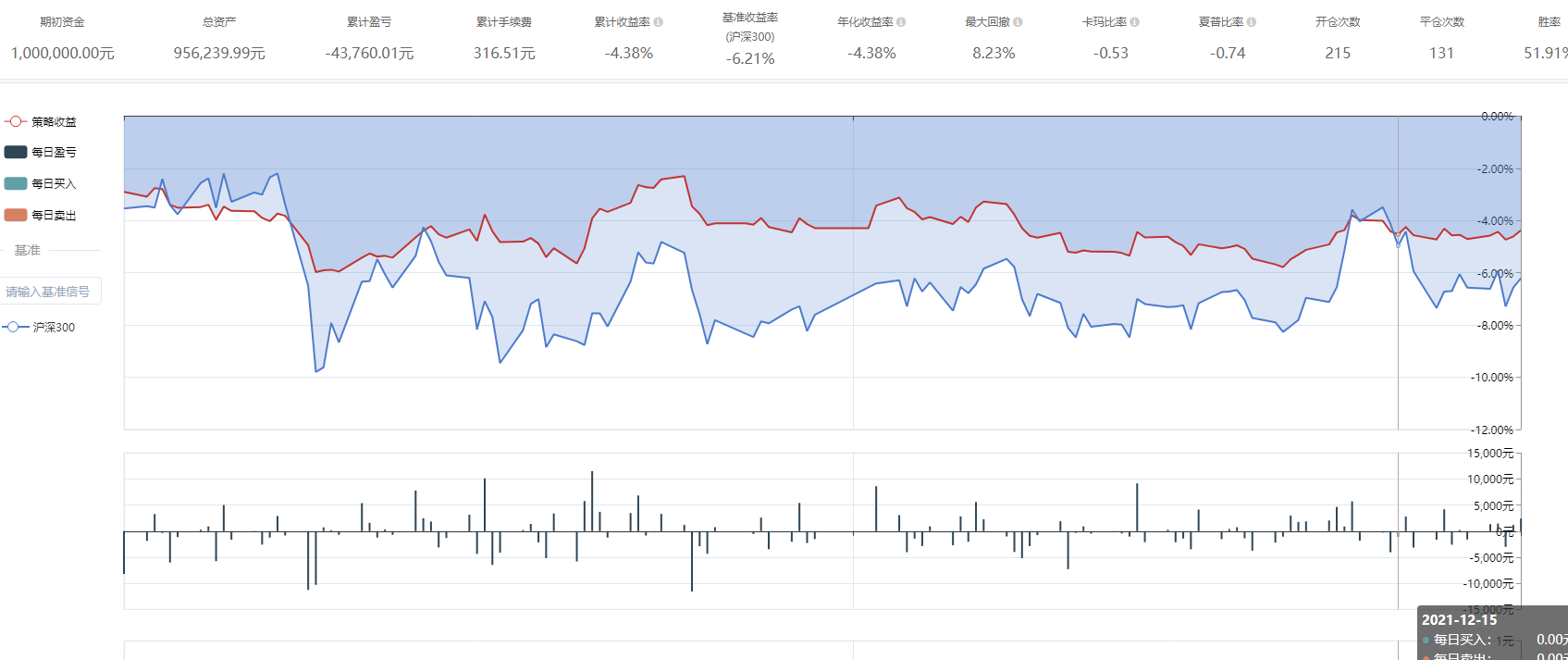
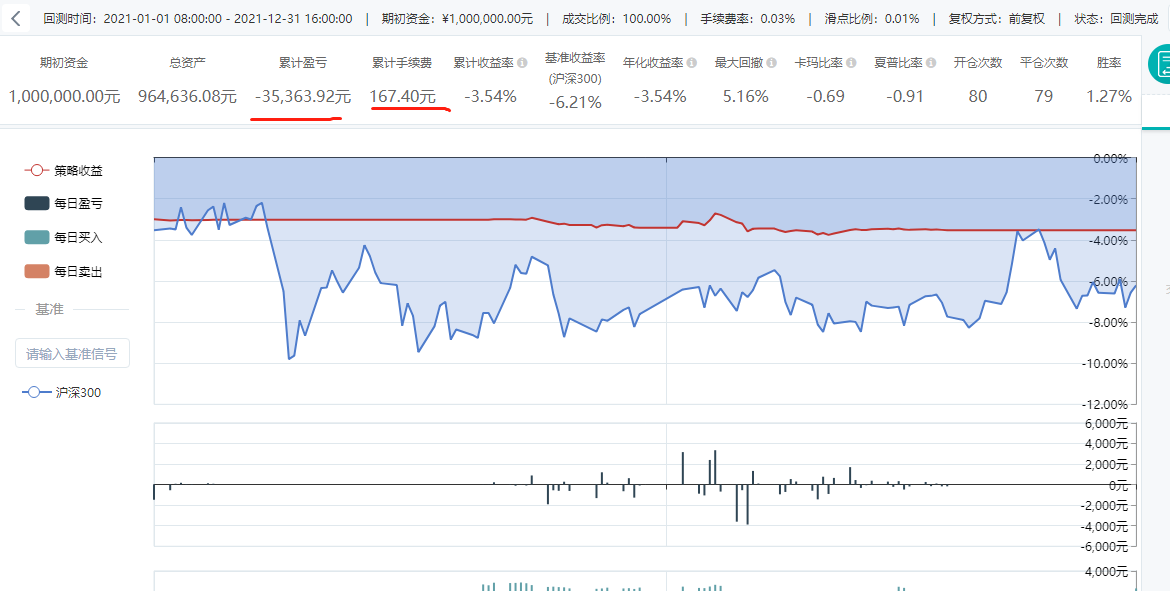
这玩意好像不怎么灵光啊,一年亏3,4个点,略好于指数
chp5 TA-Lib金融库使用详解
官网称其为TA-Lib 技术分析库,是一种以Python为基础的广泛用于量化交易中对金融市场数据进行分析的函数库。Technical Analysis Library,主要功能是计算行情数据的技术分析指标,用来开发技术分析策略
https://pypi.org/project/TA-Lib/
忽略一下这个不知道哪一家的 文档:https://technical-analysis-library-in-python.readthedocs.io/en/latest/
安装 :pip install TA-Lib
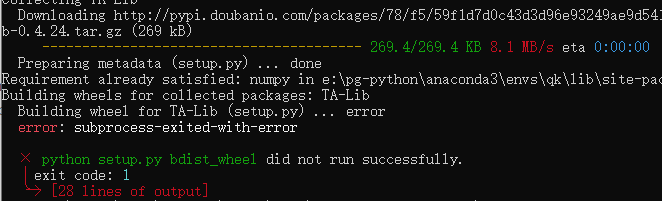
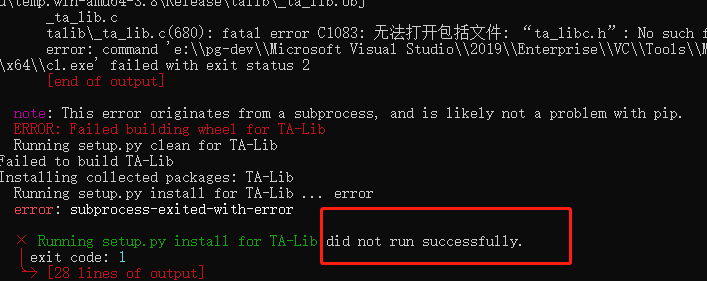
https://github.com/mrjbq7/ta-lib
安装
Windows
Download ta-lib-0.4.0-msvc.zip and unzip to C:\ta-lib.
This is a 32-bit binary release. If you want to use 64-bit Python, you will need to build a 64-bit version of the library. Some unofficial (and unsupported) instructions for building on 64-bit Windows 10, here for reference:
- Download and Unzip
ta-lib-0.4.0-msvc.zip - Move the Unzipped Folder
ta-libtoC:\ - Download and Install Visual Studio Community 2015
- Remember to Select
[Visual C++]Feature
- Remember to Select
- Build TA-Lib Library
- From Windows Start Menu, Start
[VS2015 x64 Native Tools Command Prompt] - Move to
C:\ta-lib\c\make\cdr\win32\msvc - Build the Library
nmake
- From Windows Start Menu, Start
You might also try these unofficial windows binaries for both 32-bit and 64-bit:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#ta-lib
下载了一个 TA_Lib‑0.4.24‑cp38‑cp38‑win_amd64.whl 包
$pip install wheel
安装whl包 $pip install TA_Lib‑0.4.24‑cp38‑cp38‑win_amd64.whl
与掘金量化数据库进行通信必须使用对应的账户与密码
取得日均线 talib.MA()

EXPMA指标,是一种趋向类指标,是以指数式递减加权的移动平均。
对应函数:talib.EMA()

MACD称为指数平滑移动平均线,是金融分析指标中常用的一个数据指标,用于对股票趋势的分析
对应函数:macd, signal, hist = talib.MACD(close)
macd, signal, hist = talib.MACD(close, fastperiod=x, slowperiod=y
signalperiod=z)
画出图来,长得和股票软件里的还是挺象的,
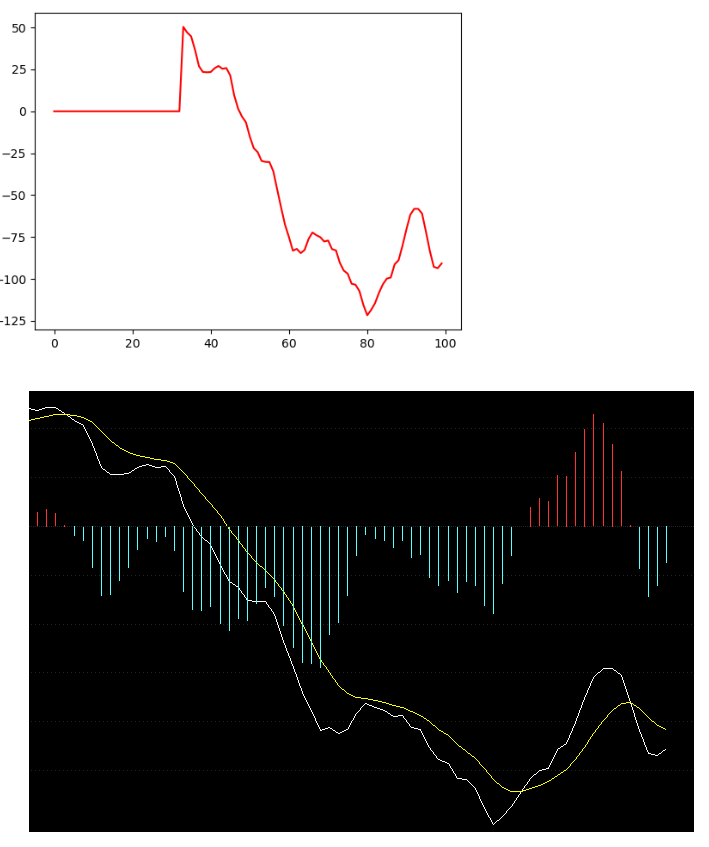
对于上涨的快慢,斜率表示一条直线(或曲线的切线)关于(横)坐标轴倾斜程度的量。它通常用直线(或曲线的切线)与(横)坐标轴夹角的正切,或两点的纵坐标之差与横坐标之差的比来表示。
使用diff函数计算MACD斜率数值的方法
macd_gradient = np.diff(macd)
回测实战
init函数是回测程序的初始化程序,在这里进行数据的初始化,从本代码段中可以看到,这里通过context初始化了目标代码、时间周期以及所需要读取的字典。最后通过schedule函数对回测的执行规则做了设定,选择了回测算法以及时间规则。
def init(context):
#股票代码 宋城演艺
context.symbol = "SZSE.300144"
context.frequency = "1d"
context.fields = "open,high,low,close"
#每次购买股数
context.volume = 2000
schedule(schedule_func=algo, date_rule="1d", time_rule="09:35:00")
回测策略的关键是算法的设定。根据不同的金融产品对象设置不同的分析算法从而决定买卖点。
def algo(context):
now = context.now
last_day = get_previous_trading_date("SZSE", now)
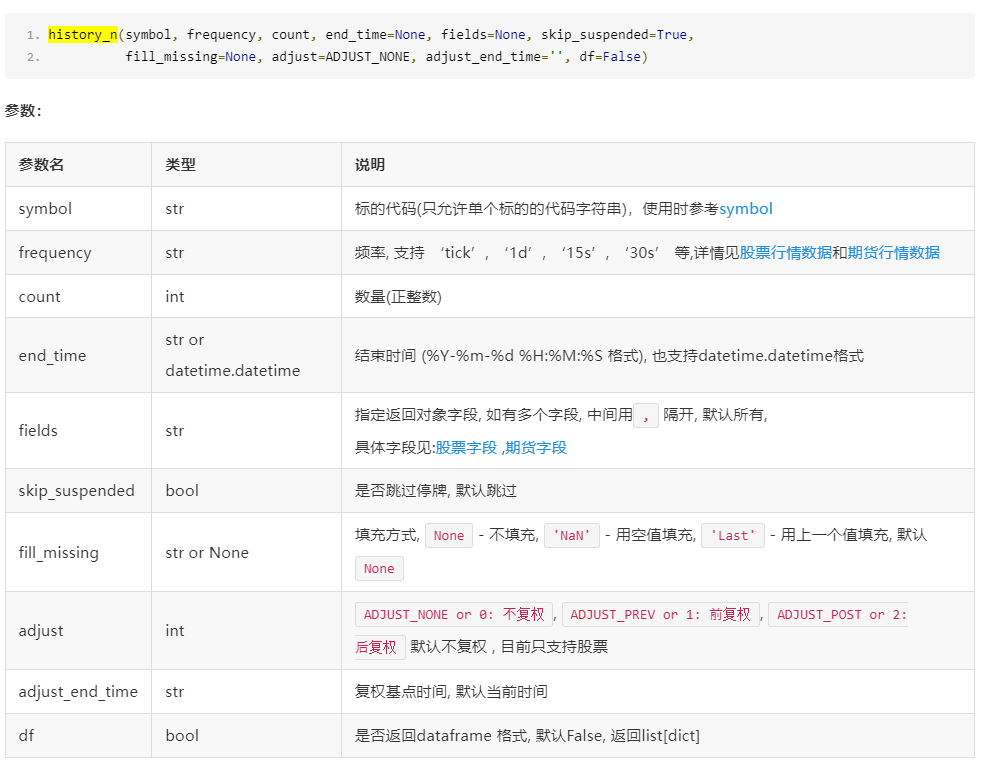
data = history_n(symbol=context.symbol, frequency=context.frequency, count=35,
end_time=now, fields=context.fields, fill_missing="last", adjust=ADJUST_PREV, df=True)
open = np.asarray((data["open"].values))
high = np.asarray((data["high"].values))
low = np.asarray((data["low"].values))
close = np.asarray((data["close"].values))
macd, _, _ = talib.MACD(close)
macd = macd[-1]
if macd > 0:
order_volume(symbol=context.symbol, volume=context.volume, side=PositionSide_Long,
order_type=OrderType_Market, position_effect=PositionEffect_Open)
print("买入")
elif macd < 0:
print("卖出")
order_volume(symbol=context.symbol, volume=context.volume, side=PositionSide_Short,
order_type=OrderType_Market, position_effect=PositionEffect_Close)
主方法中主要对账户信息、Python代码的名称、执行的类型、起止时间、复权方法进行设定。
if __name__ == '__main__':
'''
strategy_id策略ID, 由系统生成
filename文件名, 请与本文件名保持一致
mode运行模式, 实时模式:MODE_LIVE回测模式:MODE_BACKTEST
token绑定计算机的ID, 可在系统设置-密钥管理中生成
backtest_start_time回测开始时间
backtest_end_time回测结束时间
backtest_adjust股票复权方式, 不复权:ADJUST_NONE前复权:ADJUST_PREV后复权:ADJUST_POST
backtest_initial_cash回测初始资金
backtest_commission_ratio回测佣金比例
backtest_slippage_ratio回测滑点比例
'''
run(strategy_id='d570d331-a218-11ec-9ce7-c46xxxx0',
filename='main.py',
mode=MODE_BACKTEST,
token='1d2786e4ef9b90911axxxx1a2573e7',
backtest_start_time='2021-01-01 08:00:00',
backtest_end_time='2021-12-31 16:00:00',
backtest_adjust=ADJUST_PREV,
backtest_initial_cash=500000,
backtest_commission_ratio=0.0003,
backtest_slippage_ratio=0.0001)
回测策略的核心是算法的使用
RSI(相对强弱指数)是通过比较一段时期内的平均收盘涨数和平均收盘跌数来分析市场买沽盘的意向和实力,从而做出未来市场的走势。一般真实使用时判定当RSI高于70时,股票可以被视为超买,是卖出的时候。当RSI低于30时,股票可以被视为超卖,是买入的时候。
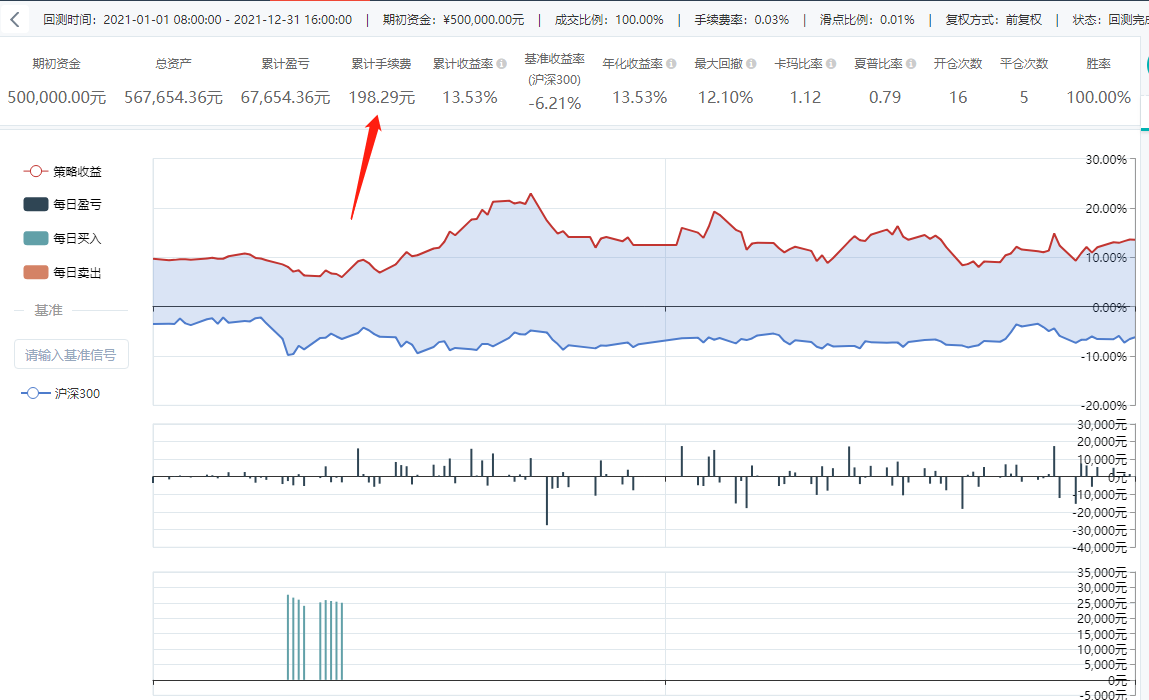
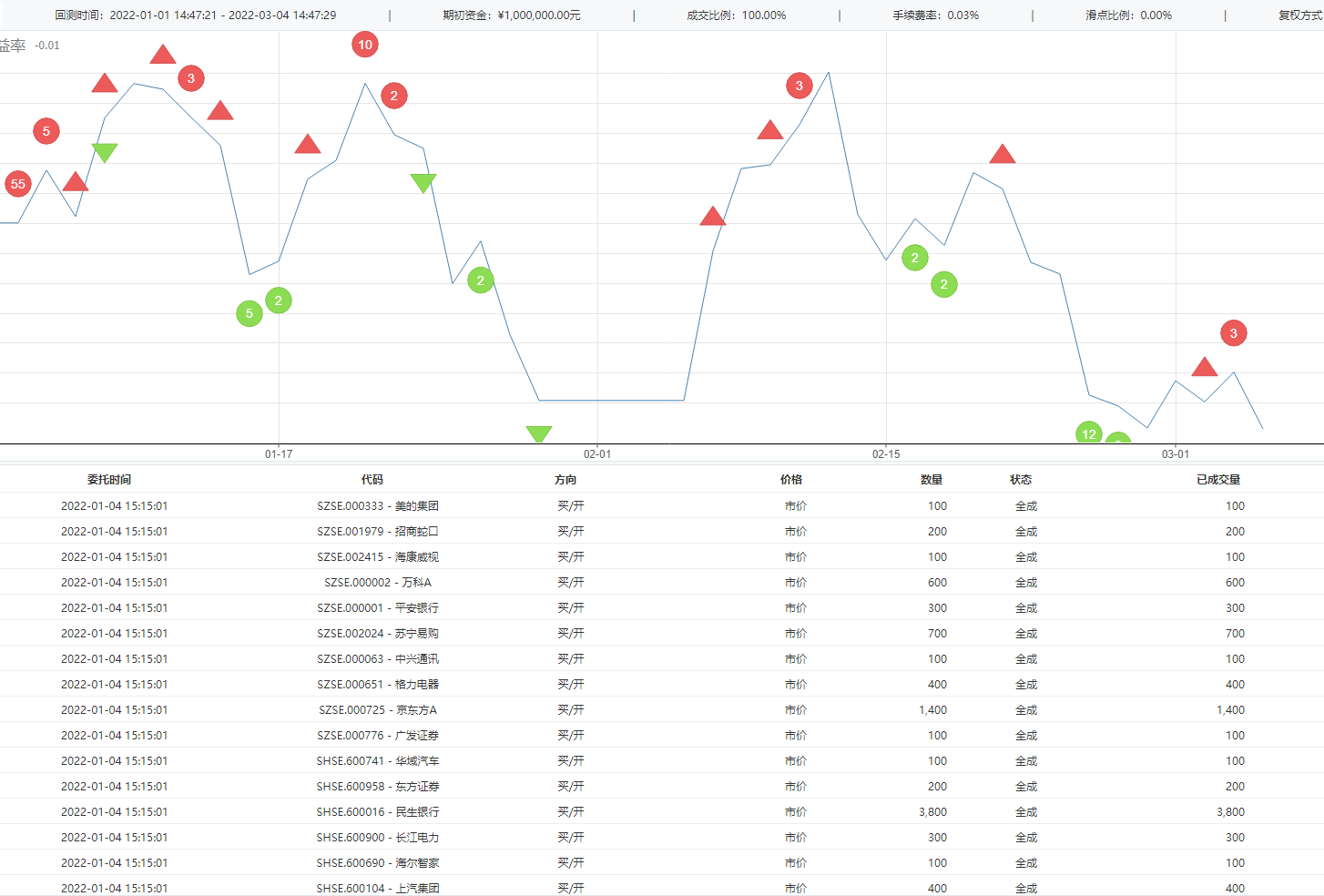
这个回测里的手续费好像少了一点。一年开仓次数16次,平仓5次,交易次数不算多,收益率13%,还是不错的。
布林线指标即BOLL指标,其英文全称是Bollinger Bands。布林线由约翰·布林先生创造,其利用统计原理求出股价的标准差以及信赖区间,从而确定股价的波动范围及未来走势,利用波带显示股价的安全高低价位,因而也被称为布林带。布林线还可以用于买卖点的设置,当股价高于这个波动区间时,即突破阻力线,说明股价虚高,执行卖出操作。而股价低于这个波动区间,即跌破支撑线,说明股价虚低,执行买入。
轨道线是趋势线概念的延伸,当股价沿道趋势上涨到某一价位水准时会遇到阻力,回档至某一水准时价格又获得支撑,轨道线就在接高点的延长线及接低点的延长线之间上下来回,当轨道线确立后,股价就可以非常容易地找出高低价位所在,投资人可依此判断来操作股票。
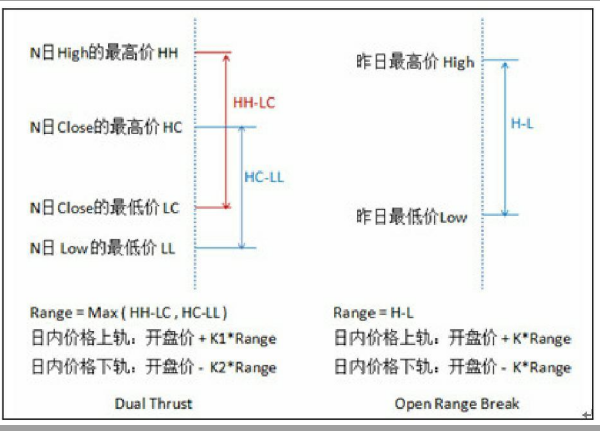
Dual Thrust策略
Dual Thrust简称DT,是Michael Chalek在80年代开发的,属于开盘区间突破类交易系统,以今日开盘价加/减一定比例的昨日振幅确定上下轨,。日内突破上轨时平空做多,突破下轨时平多做空。
chp6 多因子策略
国内A股的相关因子
1.规模因子:小市值因子
2.技术因子:动量反转因子。动量反转因子是典型的技术因子,指的是单个标的涨跌幅度的反转效应明显。
3.预测因子:预测收入的因子。预测因子指的是能够预测下一个财务周期的各种因子。
九类因子
规模因子,如总市值、流通市值、自由流通市值。
估值因子,如市盈率(TTM)、市净率、市销率、市现率、企业价值倍数。
成长因子,如营业收入同比增长率、营业利润同比增长率、归属于母公司的近利润同比增长率、经营活动产生的现金流金额同比增长率。
盈利因子,如净资产收益率(ROE)、总资产报酬率(ROA)、销售毛利率、销售净利率。
动量反转因子,如前一个月涨跌幅、前2个月涨跌幅、前3个月涨跌幅、前6个月涨跌幅。
交投因子,如前一个月日均换手率。
波动因子,如前一个月的波动率、前一个月的振幅。
股东因子,如户均持股比例、户均持股比例变化、机构持股比例变化。
一致性预测因子,如研报或者分析师预测当年净利润增长率、主营业务收入增长率、最近一个月预测净利润上调幅度、最近一个月预测主营业务收入上调幅度、最近一个月上调评级占比
选取因子的第一步就是从掘金量化所提供的财务数据表(掘金量化主界面→帮助中心→数据文档)中抽取特定的数据。函数:get_fundamentals_n()
建立股票池: get_history_constituents – 查询指数成份股的历史数据
在金融系统中产生能够表述某一方面问题的因子越来越多,大概可以分为估值与市值类因子、偿债能力和资本结构类因子、分析师预期类因子、均线型因子、成交量型因子、成长能力类因子、每股指标因子、现金流指标因子、盈利能力和收益质量类因子、能量型因子、营运能力类因子、超买超卖型因子、趋势型因子这些大类。
因子IC法来自于多因子模型的打分法,指的是选用若干能够对股票未来时间段收益产生预测作用的因子,根据每个因子在对应位置的状况给出股票在该位置上的得分,然后按照一定的权重将各个因子的得分相加,从而得到该股票各个因子的最终得分。
在打分模型中,各个因子的权重设定和计算非常重要

IC的计算公式实际上就是不同序列的相关系数的计算,那么IC值的计算用一句话解释就是:“IC值为因子与对应的下期收益率之间的关系”
corr = np.corrcoef()IC值的计算方法,即回归法。就是用该期的股票收益率对上期的因子值做回归,并用该期的因子值预测下期股票的收益率,取下期预测的收益率和下期实际收益率的相关系数。
在量化形式上,成长型投资主要是通过ROE、ROA、ROIC、营业收入增长率、主营业务利润率等参数来挖掘成长性相对更高的股票。
构建成长模型。将ROIC列为质量指标,另外构建包括EBITG(息税前收益增长率)、NPG(净利润增长率)、MPG(主营利润增长率)、GPG(毛利润增长率)、OPG(营业利润增长率)、OCG(经营现金流增长率)、NAG(净资产增长率)、EPSG(每股收益增长率)、ROEG(净资产收益率增长率)、GMPG(毛利率增长率)10个考核公司成长能力的指标。
要使用的因子:函数get_fundamentals_n()
霍华·罗斯曼认为只要在适当的价格买入稳定且持续成长获利的股票,不需要经常更换持股,投资报酬率必然指日可期。
霍华·罗斯曼强调其投资风格在于为投资大众建立均衡且以成长为导向的投资组合。其选股方式偏好大型股、管理良好且领导产业趋势以及产生实际报酬率的公司,不仅重视公司产生现金的能力,也强调有稳定成长能力的重要性。
(1)总市值大于等于50亿美元。(2)良好的财务结构。(3)较高的股东权益报酬。(4)拥有良好且持续的自由现金流量。(5)稳定持续的营收成长率。(6)优于比较指数的盈余报酬率。
用程序语言组织起来:(1)总市值≥市场平均值*1.0。(2)最近一季流动比率≥行业平均值。(3)近四季股东权益报酬率≥市场平均值。(4)最近三年CPS≥0且最近四季CPS≥0。(5)近四季营收成长率为6%至30%。(6)近四季盈余成长率为8%至50%。
chp7 带技术指标的多因子策略
技术面因子作为多因子策略的重要组成部分,已经越来越多地被量化基金和程序设计人员所使用。其主要作用是作为基本面选股的一个重要补充,解决了基本面选股策略中对买入时机的选择有所欠缺的问题。
基本面因子本质来源于公司的财务、供销、利润以及产出
技术面因子的组合计算更多涉及数学、统计等

一个回测成功率100%的中长线买卖例子
买点:
找到昨天之前成交量大于昨天的成交量(0.8倍),这个区间的天数大于30天。
昨天单日成交量大于该区间的平均成交量的2倍。
区间价格波动小于10%。
卖点:
5日均线值超过30日均线值的10%且换手率大于15。
5日均线值超过30日均线值的20%。
chp8 人人都是基金经理——中证红利指数增强策略
红利策略最初叫作“狗股策略”(Dogs of the Dow Theory),是由美国基金经理迈克尔·奥希金斯在1991年提出的。该策略的具体做法是每年年底在道琼斯工业平均指数成分股中找出10只股息率最高的股票,新年买入,一年后按股息率高低更新股票池,如此循环往复。
中证红利指数简称“中证红利”,指数代码为000922(上海)/399922(深圳)
关注。
股息率:股息率(Dividend Yield Ratio)是一年的总派息额与当时市价的比例。以占股票最后销售价格的百分数表示年度股息,该指标是投资收益率的简化形式。股息率是股息与股票价格之间的比率。在投资实践中,股息率是衡量企业是否具有投资价值的重要标尺之一。
市净率:市净率指的是每股股价与每股净资产的比率。市净率可用于股票投资分析,一般来说市净率较低的股票,投资价值较高,相反则投资价值较低。但在判断投资价值时,还要考虑当时的市场环境以及公司经营情况、盈利能力等因素。
市盈率:市盈率(Price Earnings ratio,即P/E ratio)也称“本益比”“股价收益比率”或“市价盈利比率”。
贝塔值:与大盘的联动波动率。
自相关波动率:自身的波动率。
构建一个基于指数的指数增强组合的步骤如下:
(1)根据自己的目标找到对应特征的指数。
(2)综合采用多个因子增强指数的特征。
chp 9 回归分析基础
多因子策略,就是根据各个因子的大小对股票进行打分,然后按照一定的权重加权得到一个总分,最后根据总分再对股票进行筛选。对于多因子模型的评价而言,实际上通过评分法回测出的股票组合收益率,就能够对备选的选股模型做出优劣评价
回归分析预测法是在分析市场现象自变量和因变量之间相关关系的基础上,建立变量之间的回归方程,并将回归方程作为预测模型,根据自变量在预测期的数量变化来预测因变量关系,大多表现为相关关系。
在处理测量数据时,经常要研究变量之间的关系。变量之间的关系一般分为两种,一种是完全确定关系,即函数关系;另一种是相关关系,即变量之间既存在着密切联系,但又不能由一个或多个变量的值求出另一个变量的值。
对于彼此联系比较紧密的变量,人们总希望建立一定的公式,以便变量之间互相推测。回归分析的任务就是用数学表达式来描述相关变量之间的关系。
回归分析的任务就是用数学表达式来描述相关变量之间的关系。
分为一元回归分析预测法和多元回归分析预测法。在一元回归分析预测法中,自变量只有一个,而在多元回归分析预测法中,自变量有两个以上。依据自变量和因变量之间的相关关系不同,可分为线性回归预测和非线性回归预测。
回归算法是一种基于已有数据的预测算法,其目的是研究数据特征因子与结果之间的因果关系。
y=a+βx+ε
一元线性回归模型。其中是常数。随机扰动项是无法直接观测的随机变量。
一般为了便于求解,将上述公式表示为:
y=a+bx
a是样本回归方程的常数项,也就是样本回归直线在Y轴上的截距,表示除自变量X以外的其他因素对因变量Y的平均影响量;b是样本回归系数,即样本回归直线的斜率,表示自变量X每增加一个单位,因变量Y的平均增加量。
每个回归模型都可以由一个回归函数表现出来,这样能够较好地表现出特征与结果之间的关系。
多元回归是指一个因变量(预报对象)、多个自变量(预报因子)的回归模型。基本方法是根据各变量的值算出交叉乘积和
由于各个自变量的单位可能不一样,因此自变量前系数的大小并不能说明该因素的重要程度
最小二乘法(LS算法)是一种数学优化技术,也是一种回归分析的常用解法。它通过最小化误差的平方和寻找数据的最佳函数匹配。
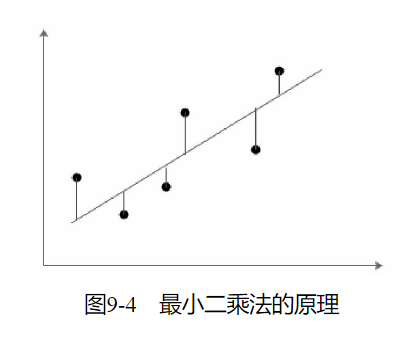
若干个点依次分布在向量空间中,如果希望找出一条直线和这些点达到最佳匹配,最简单的方法就是希望这些点到直线的值最小,即下面的最小二乘法实现公式最小
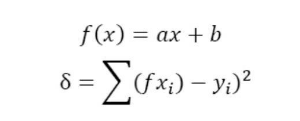
对于给定的数据(xi,yi)(i=1,…,m),在确定的假设空间H中,求解f(x)∈H,使得残差δ=∑(f(xi)-yi)2的L2-范数最小。
import statsmodels.api as sm x_ = sm.add_constant((x1)) model = sm.OLS(y, x_) results = model.fit()
随机梯度算法的原理 : 在下降一个梯度的阶层后,寻找一个当前获得的最大坡度继续下降。随机梯度下降算法就是不停地寻找某个节点中下降幅度最大的那个趋势进行迭代计算,直到将数据收缩到符合要求的范围为止。
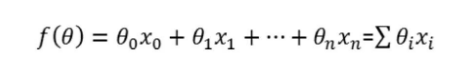
逻辑回归是一种广义的线性回归分析模型,常用于数据挖掘、疾病自动诊断、经济预测等领域。
逻辑回归的主要用途如下。
寻找危险因素:寻找某一疾病的危险因素;
预测:如果已经拟合出回归模型,那么可以根据模型预测在不同自变量的情况下发生某病或某种情况的概率有多大。
判别:根据逻辑回归模型判断某人属于某病或属于某种情况的概率有多大。
支持向量机实际上是一种有监督的机器学习算法,支持向量机解决的是有监督的二元分类问题(supervised binary classification)。
SVM的作用对象是样本的特征空间(feature space),它是一个有限维度的向量空间,每个维度对应着样本的一个特征,而这些特征组合起来可以很好地描述被分类的样本。
SVM算法会根据历史数据在特征空间内构建一个超平面(hyperplane),它将特征空间线性分割为两部分,对应着分类问题的两类,分别位于超平面的两侧。构建超平面的过程就是模型训练过程。对于一个给定的新样本,根据它的特征值,它会被放在超平面两侧中的某一侧,这便完成了分类。SVM是一个非概率的线性分类器。这是因为SVM模型回答的是非此即彼的问题,新样本会被确定地分到两类中的某一类。
SVM的强大之处在于,它不仅仅局限于是一个高维空间的线性分类器。它通过非线性的核函数(kernel functions)把原始的特征空间映射到更高维的特征空间(可以是无限维的),在高维空间中再将这些样本点线性分割。
chp10 回归模型的经典应用
资本资产定价模型(Capital Asset Pricing Model,CAPM)是由美国学者夏普(William Sharpe)、林特纳(John Lintner)、特里诺(Jack Treynor)和莫辛(Jan Mossin)等人于1964年在资产组合理论和资本市场理论的基础上发展起来的。
CAPM资产定价模型假设所有投资者都按马科维茨的资产选择理论进行投资,对期望收益、方差和协方差等的估计完全相同,投资人可以自由借贷。基于这样的假设,CAPM资产定价模型研究的重点在于探求风险资产收益与风险的数量关系,即为了补偿某一特定程度的风险,投资者应该获得多少的报酬率。
CAPM的定价模型
定价模型如下:
Ra=rf+βa×(rm-rf)
rf(Risk Free Rate)是无风险回报率(相对于一年期国债)。
βa是证券的Beta系数。Beta系数是用以度量一项资产系统风险的指针,是用来衡量一种证券或一个投资组合相对总体市场的波动性(volatility)的一种风险评估工具。
rm是市场期望的回报率(Expected Market Return)。
rm-rf是股票市场溢价(Equity Market Premium,EMP)。
CAPM定价模型需要大量的假设,归类如下:
投资者希望财富越多越好,效用是财富的函数,财富又是投资收益率的函数,因此可以认为效用为收益率的函数。
投资者能事先知道投资收益率的概率分布为正态分布。
投资风险用投资收益率的方差或标准差标识。
影响投资决策的主要因素为期望收益率和风险两项。
投资者都遵守主宰原则(Dominance Rule),即同一风险水平下,选择收益率较高的证券;同一收益率水平下,选择风险较低的证券。
可以在无风险折现率R的水平下无限制地借入或贷出资金。
所有投资者对证券收益率概率分布的看法一致,因此市场上的效率边界只有一条。
所有投资者具有相同的投资期限,而且只有一期。
所有的证券投资可以无限制地细分,在任何一个投资组合里可以含有非整数股份。
买卖证券时没有税负及交易成本。
所有投资者可以及时免费获得充分的市场信息。
不存在通货膨胀,且折现率不变。
投资者具有相同预期,即他们对预期收益率、标准差和证券之间的协方差具有相同的预期值。
第一,投资者是理性的,而且严格按照马科维茨模型的规则进行多样化的投资,并将从有效边界的某处选择投资组合;第二,资本市场是完美/完全市场,没有任何摩擦阻碍投资。
Fama-French三因子模型
Fama和French分别分析了原因,他们认为:
市值比较小的公司通常规模比较小,公司相对而言没那么稳定,因此风险较大,需要获得更高的收益来补偿。
此外就是账面市值比。账面市值比就是账面的所有者权益除以市值(以下简称B/M)。若B/M较高,则说明市场上对公司的估值比公司自己的估值更低。这些公司一般都是销售状况或者盈利能力不是十分好的公司,因此相对于低B/M的公司来说需要更高的收益来补偿。
一般对于股票收益的解释认为收益风险同源。市场风险是唯一能给股票带来超额收益的风险。但是基于以上两个事实的研究发现,除了市场风险外,Fama-French认为市场上还存在市值风险、账面市值比风险等,据此建立的模型被称为“Fama-French三因子模型”。
对于传统的股票模型来说,股票市场的Beta值不能解释不同股票回报率的差异。在此基础上,有实证研究表明,股票市值、账面市值比、财务杠杆(leverage)和市盈率的倒数(E/P)等指标可以很好地解释股票收益
Ri=ai+biRm+siE(SMB)+liE(HMI)+εi
Ri指的是股票相对无风险投资(一年期国债)的期望额外收益率。Ri=E(ri-rf)
Rm,为市场相对无风险投资的期望超额收益率
E(SMB)是小市值公司相对大市值公司股票的期望超额收益率,
E(HMI)则是高B/M公司股票比起低B/M公司股票的期望超额收益率,
εi 是回归残差项。
Fama-French在1993年提出三因子模型之后,Carhart在1997年提出了动量因子(Momentum)从而得到四因子模型,Fama-French 2015年在三因子的基础上继续增加了两个因子:盈利能力因子RMW和投资因子CMA,得到五因子模型。
选股的核心思想在于寻找价格低于内在价值的股票,从而获取未来价格修复的收益
PB-ROE模型介绍(Price/Book ratio-Return On Equity)
PB=股价/账面价值
ROE=[(净利润-优先股股利)/期初普通股股东权益]*100%
可以简单地理解PB-ROE就是“市净率-净资产收益率”
chp11 配对交易的魔力
相关性
对于pandas来说,相关系数并不是由pandas根函数提供的,而是由DataFrame对象内置的计算器计算出的。concat是连接函数,将不同的数据进行连接,axis是内置参数,用以决定从哪里进行连接,这里由于需要计算不同的数组之间的相关系数,因此选择将数据连接成不同的行,计算不同行之间的相关系数。
arr = pd.concat([arr_a,arr_b],axis=1)
相关系数:corr = arr.corr()
均值:np.mean()
方差:np.var()
标准差: np.std()
arr = pd.concat([arr_a,arr_b],axis=1)
协方差 :cov = arr.cov()
协方差是关于如何调节协变量对因变量的影响效应,从而更加有效地分析实验处理效应的一种统计技术,也是对实验进行统计控制的一种综合方差分析和回归分析的方法。协方差只表示线性相关的方向,取值正无穷到负无穷。也就是说,协方差为正值,说明一个变量变大,另一个变量也变大;取负值说明一个变量变大,另一个变量变小;取0说明两个变量没有相关关系。需要注意的是,协方差的绝对值不反映线性相关的程度。
相关系数不仅表示线性相关的方向,还表示线性相关的程度,取值[-1,1]。也就是说,相关系数为正值,说明一个变量变大,另一个变量也变大;取负值说明一个变量变大,另一个变量变小;取0说明两个变量没有相关关系。同时,相关系数的绝对值越接近1,线性关系越显著。通常情况下,取绝对值后,0~0.09为没有相关性,0.1~0.3为弱相关,0.3~0.5为中等相关,0.5~1.0为强相关。
配对交易是一种基于统计建模分析的交易策略,它是通过计算不同股票之间是否具有同样的趋势与走势进行股票交易的策略。
平稳性就是在一个时间序列中不随外界噪音改变而能够保持稳定不变的性质
相关系数是对两组数据集直接的相关性进行计算,而协整性是在不同的数据之间计算其差值并对其差值进行分析
两只股票的价差较为平稳,其在变化过程中,前进的方向也是一致的。这种性质被称为“协整性”。
协整性的第一步是对序列进行平稳性检验。
一般来说,平稳性分为严平稳性和弱平稳性。严平稳性是指一个序列的分布函数始终不变,而弱平稳性是指序列具有不变的统计常量。一般说的平稳性是弱平稳性。在时间序列分析中,常用“单位根检验”来判断一个过程是否为弱平稳性。
单位根检验:st = sm.tsa.stattools.adfuller(arr_a)
第一个参数为“Test Statistic”,第四个参数为测试的关键参数点。若第一个参数小于第四个参数中的“1%”所对应的值,则可认为序列没有单位根,为平稳序列;若第一个参数大于第四个参数中的“10%”所对应的值,则可认为序列存在单位根,为非平稳序列
对于非平稳序列转化为平稳序列,最简单的办法就是“差分法”。非平稳序列往往一次到两次差分之后,就会变成平稳序列。
经过一次差分计算的序列称为“一阶差分”,以此类推,经过n次差分计算的序列称为“n阶序列”。
“差分法”就是序列后一点的值减去当前点的值,用公式表示为yt-y(t-1)。值得注意的是,每一次差分之后,都会少一个序列值。
计算差分的函数:arr_b = np.diff(arr_a)
配对交易的算法
(1)找出具有较强相关性的股票,建立配对股票模式。这样一般要求其相对系数大于0.95。
(2)分别检验配对标的的平稳性,一般来说,股票都不会直接是平稳性序列,因此在其基础上检验配对的股票是否具有同阶差分协整性。
(3)做系数回归分析,确立系数和截距值。
(4)用单位根检验新生成的值残差是否平稳,若平稳,则两个时序是协整的,否则结束,实验失败。
(5)根据策略编写代码。