




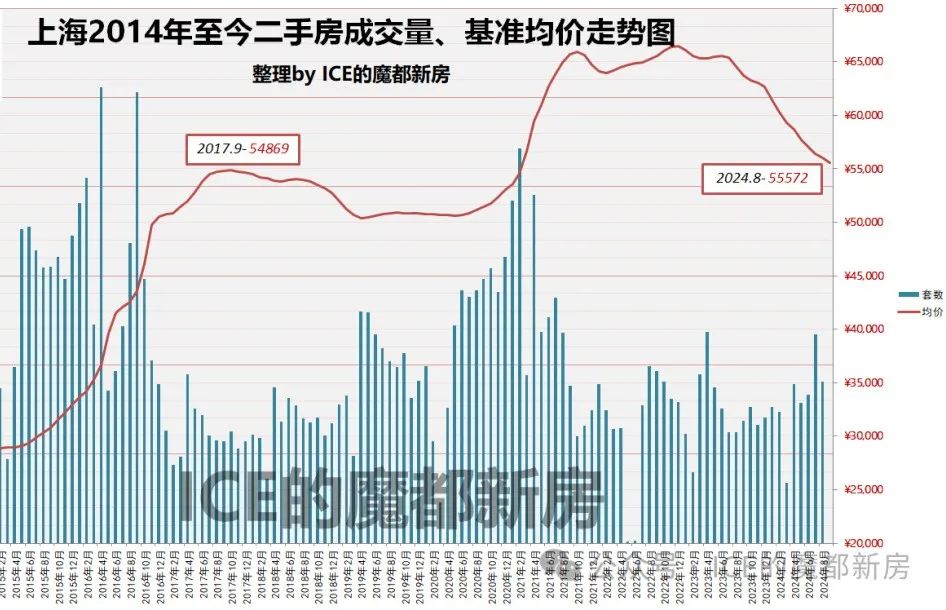




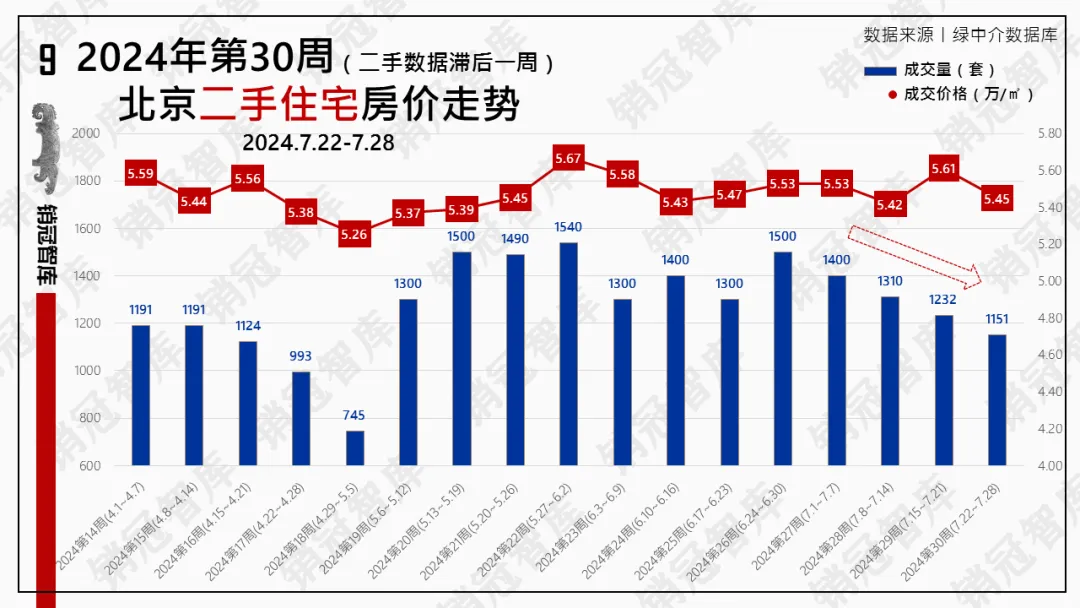


就是因为跌到这个程度,越来越多城市具备抄底价值。
跌的越狠的,越具备底部特征。
同样是下跌,但市中心明显更加抗跌,郊区全面崩塌。
作者:樱桃团队
来源:樱桃大房子(ID:ytdfz8)
转自:
分享个人经验,保留阅读记录,做时间的朋友
就是因为跌到这个程度,越来越多城市具备抄底价值。
跌的越狠的,越具备底部特征。
同样是下跌,但市中心明显更加抗跌,郊区全面崩塌。
作者:樱桃团队
来源:樱桃大房子(ID:ytdfz8)
转自:

同济大学土木工程,在宁夏的国家专项提前批中,只需要438分便可以被录取。
作为同济的王牌——土木,曾经热门的土建类专业,如今已经不再是考生们的首选。

随着房地产行业的衰退,土木工程从增量时代进入存量时代。这些种种都让大家觉得即使上了同济大学的土木专业,也不算好事。
土木是同济的王牌,但是土木不等于同济。
同济大学这所学校,还值得报考吗?
近些年同济大学的土木专业遭遇了前所未有的寒冬。同济的土木在浙江、山东、河北、重庆都遭遇滑铁卢,成了该校的最低专业分数。

相较于2023年,同济大学Q4组2024年的录取位次下降了1160位。
同济大学Q4组(生物):2024年最低541分,招生专业包含护理学。
同济大学Q5组(物理+化学):2024年最低549分,招生专业包含康复物理治疗。
同济大学Q3组(不限):2024年最低565分,招生专业包含广播电视编导。
同济大学02组(不限):2024年最低576分,招生专业包含人文科学试验班、法学、物流管理、会计学。
同济大学01组(物理+化学):2024年最低580分,招生专业包含工科试验班、经济管理试验班、理科试验班。
不难发现,同济大学01专业组投档分数线最高,当然其中的专业也是相对来说比较好就业且薪资较高的,目标是同济大学理工科专业的学生,务必好好打磨物理和化学。
建校已经113年的同济,一直以出色的工科闻名全国。不仅修起了大半个上海,在全国的土木、交通、桥梁建设中,更是随处可见同济人的身影。
同济大学是“985工程”大学、“211工程”大学、副部级大学、“双一流”建设高校A类,“土木老四所”之一。
2023年,同济大学国内软科排名第17,校友会综合排名第19,QS排名世界212名。

同济大学王牌专业众多,30个博士后,248个硕士专业,学科门类齐全。最热门的专业可能包括工科试验班、临床医学、数学与应用数学等。这些专业在同济大学可是有着非常高的知名度和录取竞争度,每年都吸引着大量优秀考生前来报考。
土木工程、建筑学、城乡规划学、风景园林学、交通运输工程、机械工程、设计学、环境科学与工程等学科已在多个主流学科排名进入全球前20名。
8个学科入选第二轮“双一流”建设学科,20个学科进入ESI全球排名前1%,其中6个学科进入ESI前千分之一。
新兴学科快速崛起,临床医学、材料科学、环境与生态、计算机、智能科学与技术、测绘科学与技术等学科进入世界前列。

2024年5月同济大学ESI上榜学科情况 图源:最佳大学
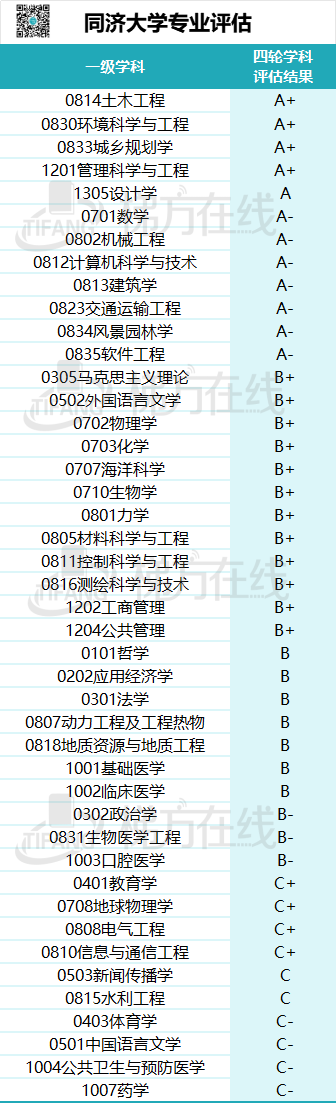
同济的工科实力整体不错,其中土木、建筑是老牌优势专业,相关专业实力都非常强,大概国内前二,然而由于行业不太景气,近两年报考热度略有下降。
同济和德国合作密切,汽车相关专业非常有名,在土木建筑之外可以考虑;信息类专业中同济的测绘挺好的,计算机、电子类专业相较交大有一定距离,但也还不错,再加上这些是热门专业,也可以考虑。
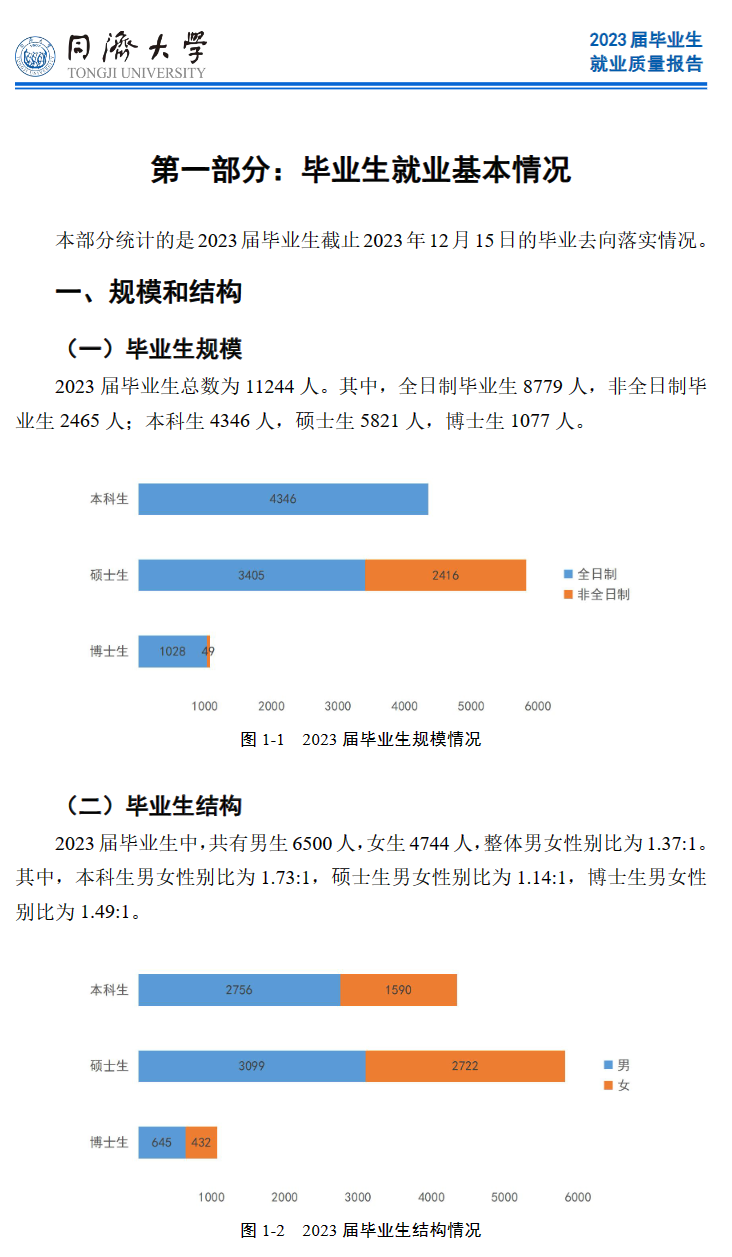
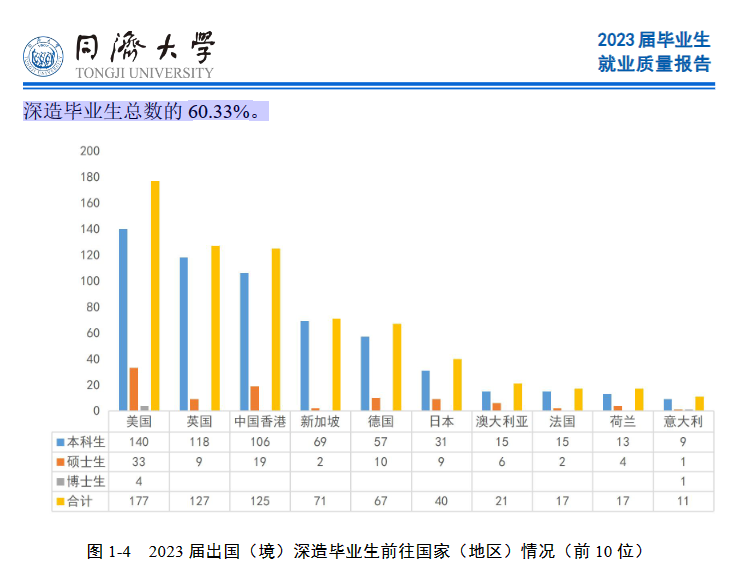
2023届毕业生总数为11244 人。男女性别比为1.37:1。其中,本科生男女性别比为1.73:1,硕士生男女性别比为 1.14:1,博士生男女性别比为 1.49:1。
其中,全日制毕业生8779人,非全日制毕业生2465 人;
本科生 4346 人,
硕士生 5821 人,
博士生 1077 人。
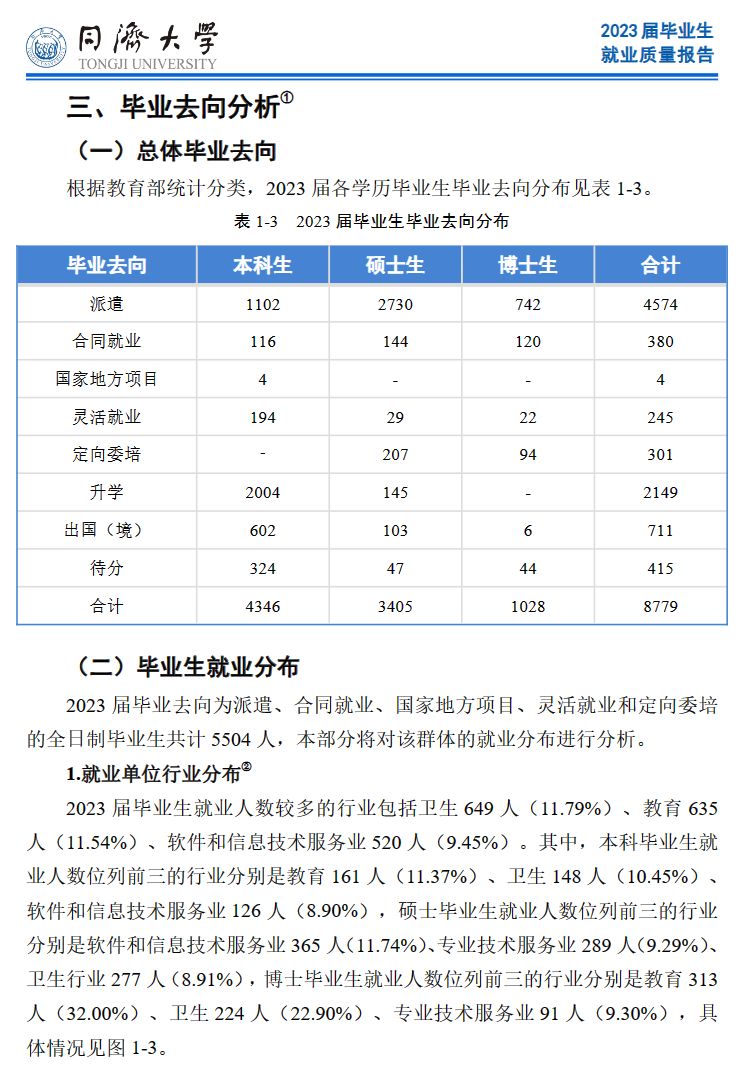
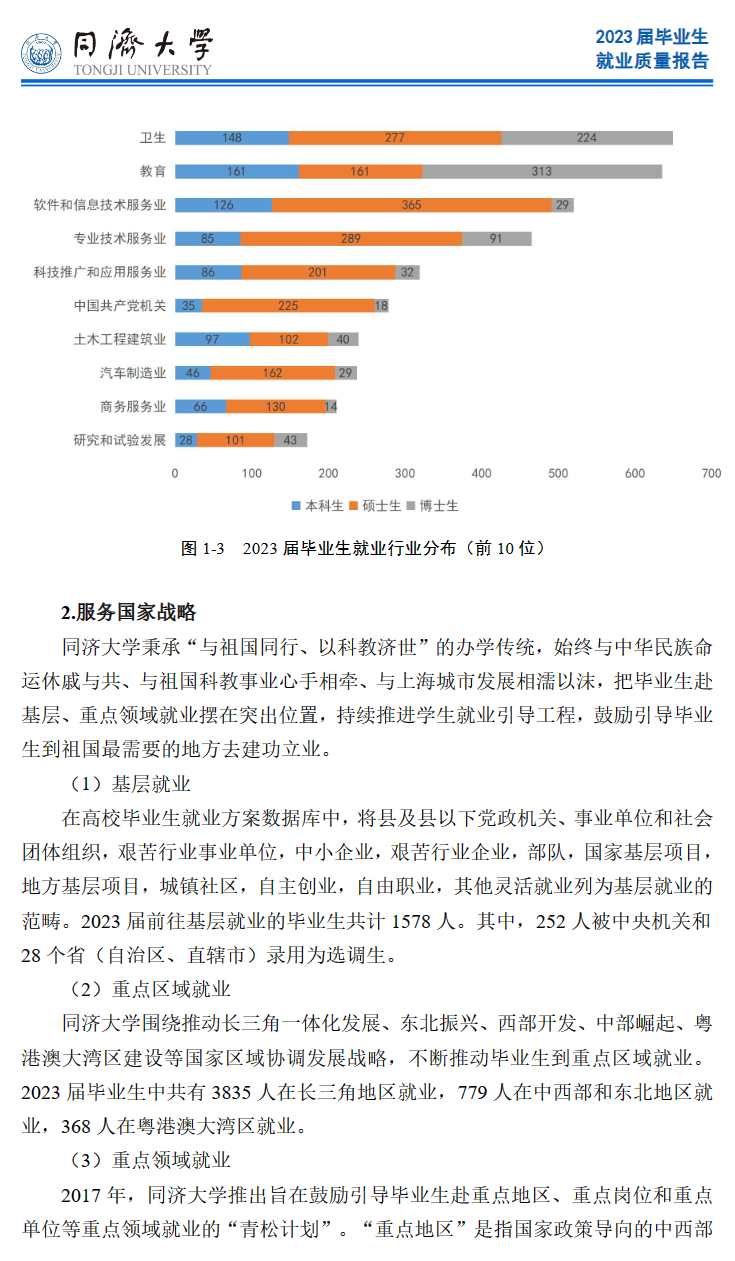
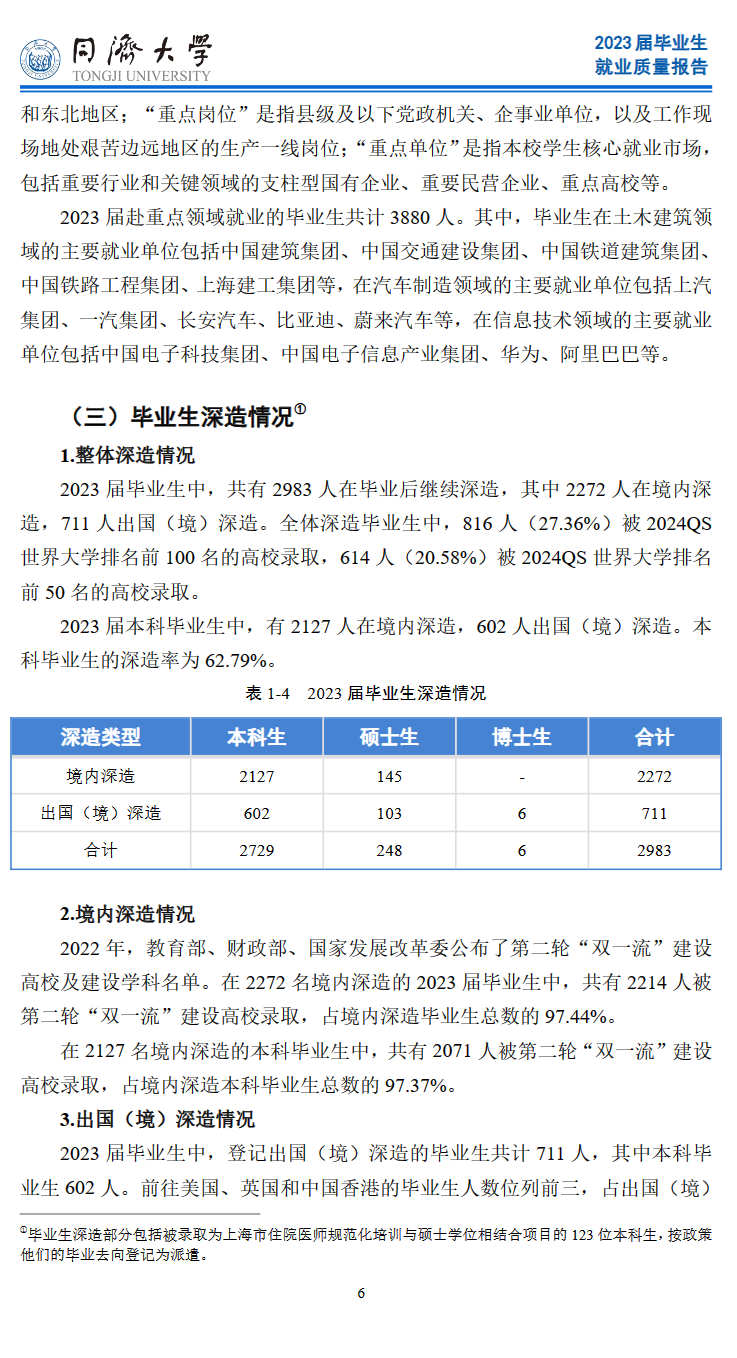
截止2023年12月15日2023 届毕业生毕业去向落实率为 96.31%。
本科生与上届相比:
国内升学同学明显增加,主要是保研增加。
出国出境留学明显反弹,略接近2020届水平。
深造人数、深造率创历史新高。如果加上规培,深造率高达62.79%。

转自: 上海升学路
历史书级别的事件发生了。
2024年7月23日,《北京宣言》公布,巴勒斯坦14个派别在中国北京达成和解,签署了关于结束分裂,加强巴勒斯坦团结的《北京宣言》,一致同意成立“临时民族和解政府”,结束巴勒斯坦持续17年的政治分裂,以人民代表大会制度进行联合执政。




转自: https://mp.weixin.qq.com/s/zW9Tv7–d5yNSAIgk-gm-Q
01
闲居初夏午睡起·其一
宋·杨万里
梅子留酸软齿牙,芭蕉分绿与窗纱。
日长睡起无情思,闲看儿童捉柳花。
绿水青山常在
吃过梅子后,余酸还残留在牙齿之间,芭蕉的绿色映照在纱窗上。
漫长的夏日,从午睡中醒来不知做什么好,只懒洋洋地看着儿童追逐空中飘飞的柳絮。
02
客中初夏
宋·司马光
四月清和雨乍晴,南山当户转分明。
更无柳絮因风起,惟有葵花向日倾。
绿水青山常在
初夏四月,天气清明和暖,下过一场雨天刚放晴,雨后的山色更加青翠怡人,正对门的南山变得更加明净了。
03
阮郎归·初夏
宋·苏轼
绿槐高柳咽新蝉,薰风初入弦。碧纱窗下水沈烟,棋声惊昼眠。
微雨过,小荷翻,榴花开欲然。玉盆纤手弄清泉,琼珠碎却圆。
绿水青山常在
这首词写的是初夏时节的生活,采用从反面落笔的手法,用一幅幅无声画来展示大自然的生机。整首词淡雅清新而又富于生活情趣。
04
幽居初夏
宋·陆游
湖山胜处放翁家,槐柳阴中野径斜。
水满有时观下鹭,草深无处不鸣蛙。
箨龙已过头番笋,木笔犹开第一花。
叹息老来交旧尽,睡来谁共午瓯茶。
绿水青山常在
湖光山色之地是我的家,槐柳树阴下小径幽幽。湖水满溢时白鹭翩翩飞舞,湖畔草长鸣蛙处处。
05
初夏即事
宋·王安石
石梁茅屋有弯碕,流水溅溅度两陂。
晴日暖风生麦气,绿阴幽草胜花时。
绿水青山常在
石桥和茅草屋绕在曲岸旁,流水流入西边的池塘。
晴朗的天气和暖暖的微风催生了麦子,麦子的气息随风而来。碧绿的树荫,青幽的绿草远胜春天百花烂漫的时节。
06
初夏游张园
宋·戴复古
乳鸭池塘水浅深,熟梅天气半晴阴。
东园载酒西园醉,摘尽枇杷一树金。
绿水青山常在
小鸭在池塘中或浅或深的水里嬉戏,梅子已经成熟了,天气半晴半阴。在这宜人的天气里,邀约一些朋友,载酒宴游了东园又游西园。
07
初夏
宋·朱淑真
竹摇清影罩幽窗,两两时禽噪夕阳。
谢却海棠飞尽絮,困人天气日初长。
绿水青山常在
竹子在微风中将清雅的影子笼罩在幽静的窗户上,成双成对的鸟儿正在夕阳下尽情地喧噪鸣叫。
在这海棠花凋谢、柳絮飞尽的初夏,只觉炎热的天气使人感到乏困,白昼也开始变得漫长。
转自:https://mp.weixin.qq.com/s/rhQuzxcUbC8OWQZ8Fkw_Yg
从鲁迅笔下的闰土,到现实中逐渐失去灵气的中年人,万维钢老师提出了一个关键命题:终身学习。在碎片化时代,保持灵气并非遥不可及的梦想,而是需要我们持续喂给大脑新鲜的知识,充分利用社交圈的力量,这不仅是为了积累知识,更是为了在各种挑战中让思维充满活力。
让我们和这篇文章一起,揭开年龄与智慧的秘密,拒绝成为“麻木的闰土”。
作者:万维钢
鲁迅把闰土的麻木归咎于社会,“多子,饥荒,苛税,兵,匪,官,绅” —— 可是现代中年人也可以说自己是负重前行。收入只有这么多,上有老下有小都在指望你拿钱。工作压力又大,又有年轻人在竞争。身体机能在下降,真有点干不动……就好像是登山一样,有的人是轻装上阵,有的人是背负着好几个沉重的包袱,他们掉队难道不是正常的吗?
这个说法,没有科学依据。
✵
现实是那些保留了灵气的中年人比麻木中年人更“忙碌”,而不是更清闲。他们要处理的事物更复杂而不是更简单,他们背的包袱更重。
一直到老年,大脑都是可塑的。我们专栏早就讲过中年人大脑的特点 。中年大脑有两方面的性能是下降的。一个是计算速度,也就是所谓「流体智力」,比如下围棋、做数学题这些事情,你到中年再练就太晚了。另一个是注意力不容易长时间集中,中年人确实爱分心。
但中年大脑的优势大于劣势。像模式识别、空间想像力、逻辑推理能力,这些能力不但没有下降,而且还上升了。而且中年人积累了大量知识,「晶体智力」是我们的特长。尤其中年人控制情绪的能力越来越好,办事稳稳当当,主打一个可靠。
并不是所有中年人都变成了闰土。鲁迅小时候似乎还没有闰土灵,可却是越老越犀利。
那迅哥儿和闰土,到底是如何拉开差距的呢?
✵
我认为「坏人变老」模型和「负重登山」模型都不对。这里我提出一个模型,大概可以叫「喂料不足」。简单说,是社会在一直进步,知识一直在更新,而闰土没有吃到足够多的训练素材。
小学生把中学生视为大人,中学生把大学生视为榜样,研究生把教授视为神明。如果你能保持学习速度,你就是可以每过几年就让自己刮目相看。可为什么有些45岁的人不如25岁的人?因为他们的知识停留在自己25岁那一年,而那一年的社会知识水平不如这一年。你不必退步,你停下就是落后。
有研究表明,人到了老年会更愿意依赖自己年轻时代——更具体的说是18岁左右的时候——形成的刻板印象处理问题,不再做复杂的思考,更愿意把问题给简单化、标签化。如果你18岁时生活在一个讲种族主义的社会,你有可能一生都是个种族主义者。哪怕现在的年轻人已经不那么想了,你还是会那么想。
人想停在自己的年轻时代可能是因为年轻时代的问题已经解决了。我的生活还不错,我有一份体面工作,我的经验足够,所以我对世界的探索已经结束。现在这些连手机支付都搞不明白的老年人,年轻时候何尝不是独当一面的能手呢?
尤其过去绝大多数工作岗位不需要持续学习。下面这张图描写了1960到2002年间,美国的工作岗位对不同技能的需求 ——
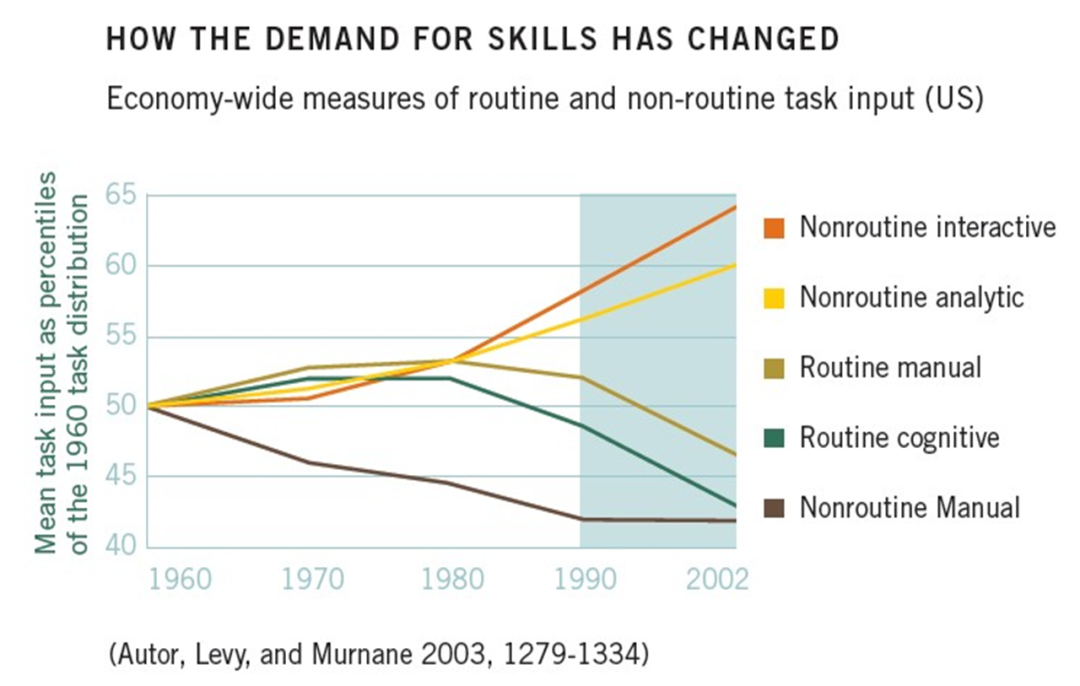
社会对那些例行公事的、程序化的体力劳动和脑力劳动的需求都在减少,而对非程序化的脑力劳动、特别是需要跟人互动的技能需求越来越大。我相信中国也是这个趋势,但是我没有数据。
这也就是说,1980年上班的年轻人,主要从事的是程序化工作。他们只要按照上级指令、用固定的流程做事就行。他们还有啥可学的?然而今天的社会已经不是那样的社会了。
好消息是我们有理由相信今天的年轻人将来老了也不至于太笨,坏消息是喂料不足是个普遍现象。哪怕是非程序化工作,大部分人也只需要凭经验应付。你不会有太强的学习动力,你的头脑会变得封闭。
✵
现在人人都爱说“开放”,咱们最好先说明白什么叫「开放的头脑」。不是说允许中国地铁用英语报站名就叫开放。
心理学家有个标准化的「积极开放式思维(Actively Open-minded Thinking, AOT)」测试,用来评估人的头脑开放程度。这个测试最关键的就是看你是否允许新事物改变你的旧观念。
也就是说你有没有贝叶斯精神:新的证据出来了,你的信念能不能做出相应的改变。如果事实跟你的信仰冲突,你是回避事实还是重新考虑你的信仰?
年轻人无所谓,信念还没有固化,可以被事实修正。但是随着年龄增长,人们越来越不愿意改变。下图中这个研究 [4] 表明,积极开放思维得分随着年龄一直在下降。
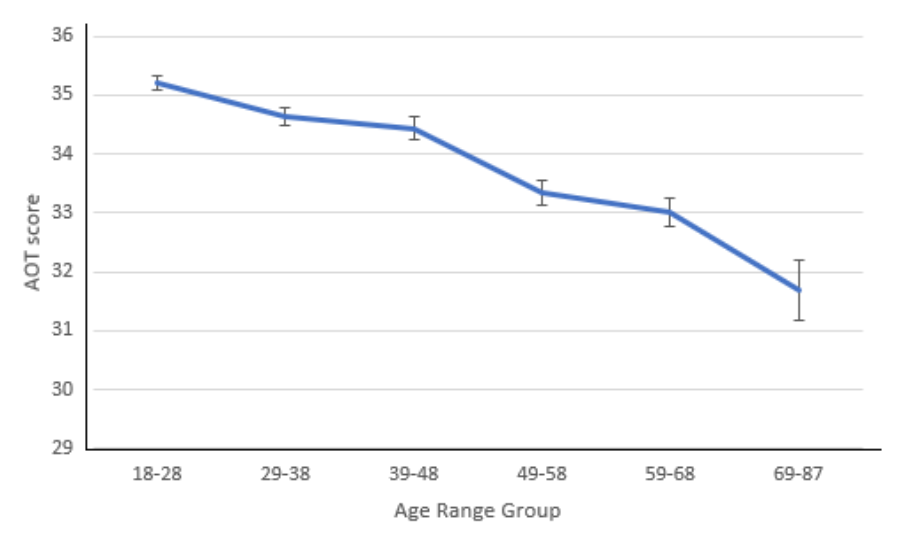
特别是在40岁和70岁,有两次剧烈的下降,正好一次是中年一次是老年。
这可能跟认知能力老化有关。比如中年人注意力难以集中的话,对新东西可能就看不太懂,也就懒得改变观点。但我们还是要强调个体之间的差异。
各种研究表明受教育程度越高的人,开放头脑得分就越高,也越能坚持终身学习,他们的思想不容易封闭。健康状况、爱不爱锻炼也很重要,另外整个社会的风气,以及有没有方便的学习渠道,这些都有关系。
但我调研发现,影响学习动力最重要的一个因素,是社交圈。
✵
2019年,有9个在南极考察站生活了14个月的科考队员,回来接受了德国科学家的测试 [5]。这14个月的封闭生活改变了他们的大脑。他们海马体上的齿状回(dentate gyrus)—— 这个脑区主要负责形成新的记忆 —— 平均缩小了7%。他们的智力测验成绩和空间距离感都下降了,他们的注意力也不像以前那么容易集中。
长期在一个与世隔绝的环境里生活,对大脑很不利。你缺少新鲜的互动,你的信息输入太少,你喂料不足。哪怕你号称是在那里做“科学考察”。
然而很多中年人就是在走向与世隔绝。年轻人因为上学和上班,总在认识新人,会有很多朋友。人到中年的普遍趋势是不再愿意认识新人。你会更愿意把时间花在家人、老朋友和老同学身上。这些熟人的问题是他们知道的信息你也早就知道。你们在共同的舒适区里玩耍。
慢慢地,连这些熟人也会离开你。有一项中国的研究 [6],考察广东省60岁以上的中老年人,发现他们是因为社交圈封闭而处于身陷「信息茧房」的状态。研究者用下面这张图描写了信息茧房的运作过程 ——
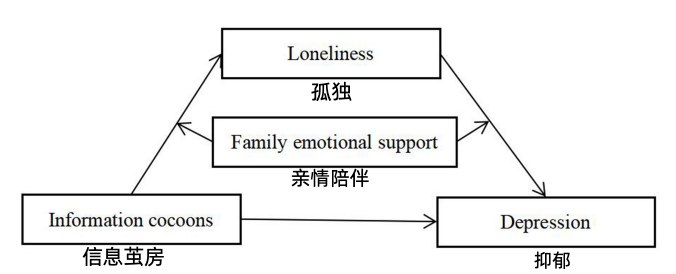
孩子已经离开家了,老人大部分时候只跟很少的人接触,于是迷上短视频,寻求情绪价值。短视频的推荐算法是专门推给你*喜欢*看的东西 —— 而不是你*应该*看的东西。而你喜欢看的是你熟悉的东西,于是信息茧房。
然而短视频提供的是虚幻的社交,那并不能解除孤独感。就好像吸毒一样:特别想吸,但是吸了又感到空虚。短视频让老人更孤独,乃至于抑郁。解决方法是家人多给点亲情陪伴,减少孤独感。
美国的数据 [7] 是45岁以上的人有超过三分之一感到孤独;65岁以上的人中甚至有将近四分之一,不仅是孤独,而且是跟社会隔绝(socially isolated)。社会隔绝会让老年痴呆症的风险增加50%,心脏病的风险增加29%。
他们也是更封闭、更固执、更不愿意继续学习的人。
✵
有些精神世界丰富的人宁可选择独处,那不叫孤独。有孤独感才叫孤独。人到中年很难有动力主动去学什么新东西,但只要你有个丰富多彩的社交圈,跟各个年龄段的人打交道,你潜移默化就能跟上社会进步的节奏。
我们专栏讲过到八九十岁还脑力充沛的「超级老年人」[8],他们有个特别不一般的共同点是「社交蝴蝶」:他们就算退休了也要继续工作,哪怕是去社区做志愿者,哪怕是多参加休闲活动。他们没有从社会退出。
这要求你始终有一股积极主动的劲头。那些接受“岁数大了脑子就不好使”这种刻板印象的人学习动力就低,那些有积极主动人格的人学习动力就高 [9]。终身学习者都是主动找事儿做,主动承担责任,主动冒险,主动社交。
最后我们重读一遍《故乡》中鲁迅先生的话:
「我又不愿意他们……都如我的辛苦展转而生活,也不愿意他们都如闰土的辛苦麻木而生活,也不愿意都如别人的辛苦恣睢而生活。他们应该有*新的*生活,为我们所未经生活过的。」
转自: https://mp.weixin.qq.com/s/fbSnJBlaQK-S7XWvCuqkxA