编者按:人生苦短,Python是岸。近年来随着人工智能和机器学习的发展,Python大火,但其实Python并不是一门年轻的语言,早在1991年它就出现了。这门编程语言已经发展了多年,在可预见的未来也会继续保持它的地位。如今是Python的世界,花时间学习Python编程语言将是你对未来最好的投资。本文译自Medium,作者Rinu
Gour,原标题为” We are Living in “The Era of Python””,希望对您有所启发。
1989年,Guido van Rossum在参加设计ABC(一种教学语言)后,萌生了想要开发一种新语言的想法。1989年他创立了python语言。1991年初python公布了第一个公开发行版。
你知道吗?
Python编程语言一点也不年轻,它是由荷兰程序员吉多·范罗苏姆(Guido van Rossum)于1991年首次发布的。
Python有意思的地方在于,他是一个人的工作成果,而大多数其他流行的编程语言都是由雇佣了大量专业人员的大公司开发和发布的。Python是个例外!
当然,并不是python的所有组件都是由范罗苏姆独自一人开发的,它是一个开源项目,成千上万的人都对Python的开发做出了贡献。尽管python经过多年的发展已经有了很大的进步,但它的使用目的与当年相差不大。
Python的诞生
开发python的主要目的是帮助程序员编写逻辑清晰的代码。这就是它在开发人员中如此流行的原因。Python非常强大,可以被用于Web开发、游戏开发、为桌面应用程序构建脚本和GUI、配置服务器、执行科学计算和进行数据分析。
Python几乎可以用于任何事情!
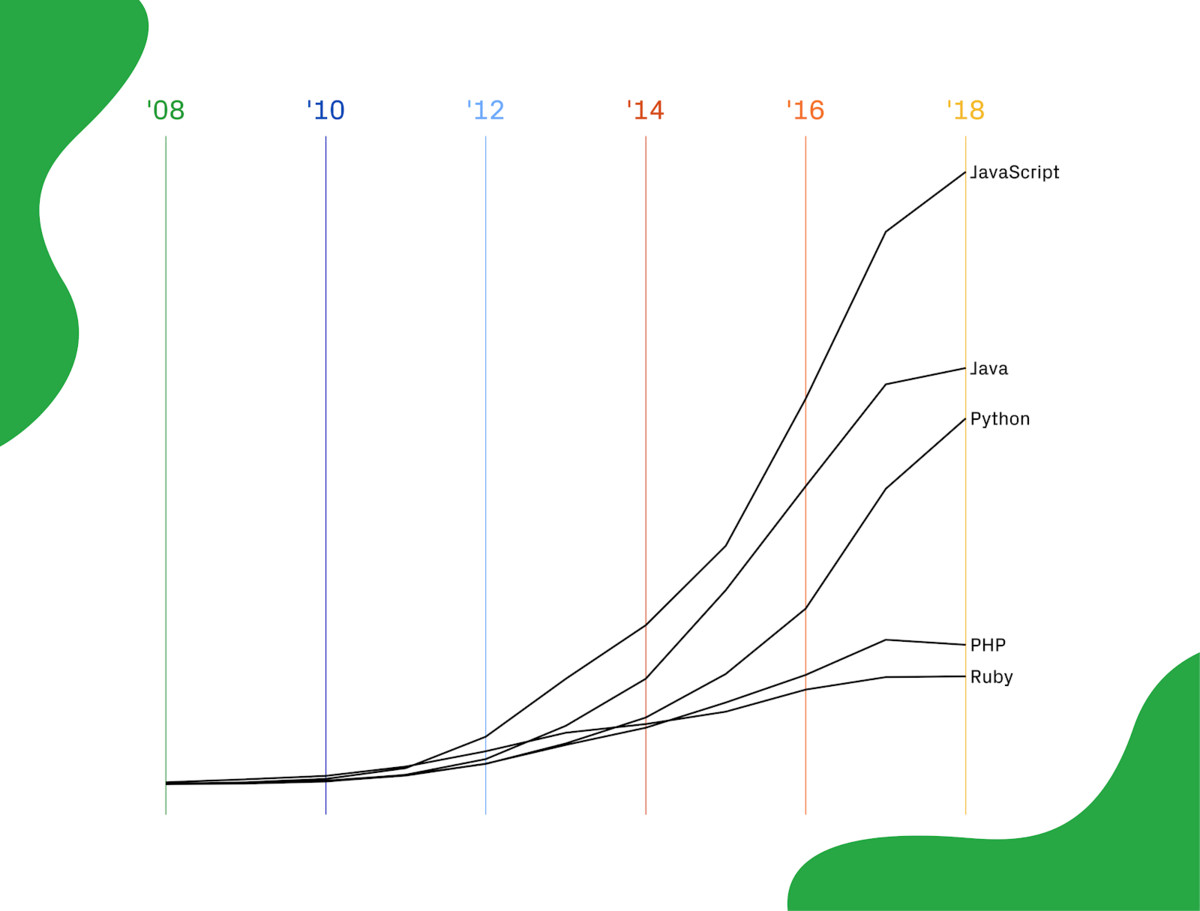
在这些主要的编程语言中,Python在最近几年发展非常迅速。Stack Overflow 开发者调查显示,Python 是增长最快的主流编程语言。
那么,这些年到底发生了什么?python为什么发展得这么快?
那是因为以下技术的发展促进了python语言的快速使用。
Python – AI的最佳选择
人工智能(AI)和机器学习(ML)技术的进步已经超越了科幻小说。
正如克里斯·达菲(Chris Duffey)在他的书《超人的创新》(Superhuman Innovati)中所说,
“人工智能的唯一限制是人类的想象力。”
如今,随着数据量的扩大,人工智能和机器学习正在处理那些在过去似乎不可能完成的任务。所有的科技巨头(Facebook、微软、谷歌、亚马逊)都在积极开张数据工作,争先恐后地为促进这些领域的发展做出贡献。
根据研究,人工智能和机器学习实践者更喜欢使用python,因为python易于编码和可读性较高,这样我们就不会被语言的结构所困扰。
Python是数据科学的支柱
世界上充满着大量的数据。全球范围内的数据如同海啸,而且数据量每天都在变得越来越大。我们现在所做的一切都都可以产生数据。不管是拍照,在社交媒体上发表评论,在网上进行搜索,网上购物……这一切都会被记录下来。
到2020年,预计每天将产生44兆字节的数据。但是,如果我们不能收集、整理、分析和应用数据来造福社会,这些数据就毫无用处。这也就是数据科学的用途。
Python在数据科学中被大量使用。python社区已经开发出了用于处理数据的优秀库,如Numpy、pandas、sci-kit-learn等。在收集数据、清理数据集、提取重要特性、构建机器学习模型和使用图形可视化结果方面,python提供了丰富的特性集来执行这些任务。
“数据科学家的工作越来迷人,”Indeed的经济学家、报告的作者安德鲁·弗劳尔斯(Andrew Flowers)说。“越来越多的雇主希望聘用数据科学家。”
Github每年都会进行一次年度调查,让我们看看Python这些年是如何增长起来的。
像Spotify、Netflix、Quora、Facebook和谷歌这样的大公司已经深入开发了Python。谷歌从一开始就支持Python,它现在是谷歌的官方服务器端语言。他们将许多用Bash或Perl编写的脚本重新编码为Python。
谷歌的研究主任彼得·诺维德(Peter Norvig)说:“从一开始,Python就一直是谷歌的重要组成部分,并且随着系统的发展和演变,到现在也是如此。如今,很多谷歌工程师使用Python,我们也正在寻找更多掌握这门语言技能的人。”
Spotify和Netflix非常依赖python来分析它们在服务器端的庞大数据量。通过分析来自数百万用户的信息,他们可以为每个用户提供更好的建议,这就是他们赚取数十亿美元利润的方式。
Python不是一门年轻的语言,它已经发展了多年,并将在未来几年继续保持它的地位。如今是Python的世界,花时间学习Python编程语言将是你对未来最好的投资。